




- @zwqjoy
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
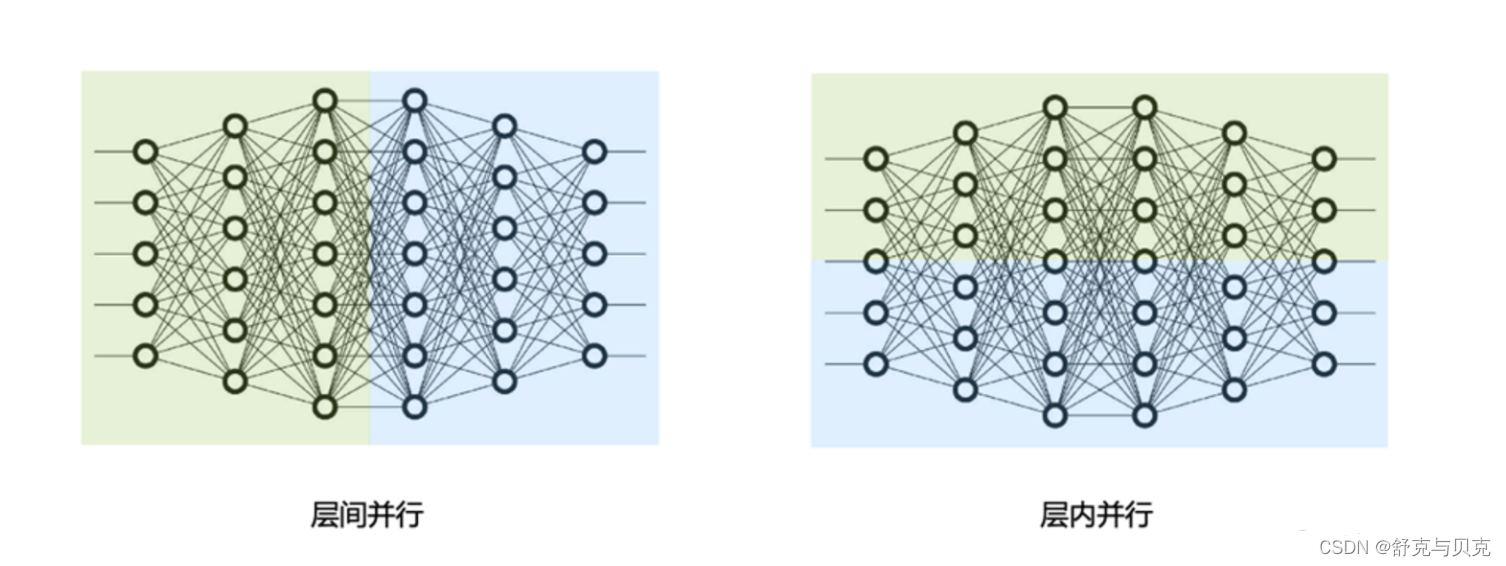
所谓流水线并行,就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。流水线并行PP(Pipeline Parallelism),是一种最常用的并行方式,也是最初Deepspeed和Megatron等大模型训练框架都支持的一种并行方式。如下图所示,模型共包含四个模型层(如:Transformer层),被
机器学习面试题的分类The first really has to do with the algorithms and theory behind machine learning. You’ll have to show an understanding of how algorithms compare with one another and how to measure their ..
一、相关理论本篇博文主要介绍南京大学周志华教授在2017年提出的一种深度森林结构——gcForest(多粒度级联森林)。近年来,深度神经网络在图像和声音处理领域取得了很大的进展。关于深度神经网络,我们可以把它简单的理解为多层非线性函数的堆叠,当我们人工很难或者不想去寻找两个目标之间的非线性映射关系,我们就多堆叠几层,让机器自己去学习它们之间的关系,这就是深度学习最初的想法。既然神经网络可以堆叠..
一 深度可分离卷积深度可分离卷积之所以如此命名,是因为它不仅处理空间维度,还处理深度维度-通道的数量。通常输入图像可以有3个通道:RGB。经过几次卷积后,一个图像可能有多个通道。你可以把每个频道想象成那个图像的一个特殊解释;例如,“红色”通道解释每个像素的“红色”,“蓝色”通道解释每个像素的“蓝色”,“绿色”通道解释每个像素的“绿色”。一个有64个频道的图像有64种不同的解释。深度可分离卷...
一 说明在对不平衡数据进行训练时,通常会考虑一下怎么处理不平衡数据能使训练出来的结果较好。能想到的比较基础的方法是过采样和下采样来缓解数据中的正负样本比。在用xgboost训练二分类模型时,除了直接使用过采样和下采样,xgboost接口还提供一些处理不平衡数据的方法,有scale_pos_weight参数的设置,还有给样本赋予一定的权重。接下来让我们仔细看一下吧~参数scale_pos_weigh
1.文本数据的向量化1.1名词解释CF:文档集的频率,是指词在文档集中出现的次数DF:文档频率,是指出现词的文档数IDF:逆文档频率,idf = log(N/(1+df)),N为所有文档的数目,为了兼容df=0情况,将分母弄成1+df。TF:词在文档中的频率TF-IDF:TF-IDF= TF*IDF1.2 TF-IDF算法TF-IDF(词频-逆文档频率)算法是一...
背景介绍与评分卡模型的基本概念如今在银行、消费金融公司等各种贷款业务机构,普遍使用信用评分,对客户实行打分制,以期对客户有一个优质与否的评判。交易对手未能履行约定契约中的义务而造成经济损失的风险,即受信人不能履行还本付息的责任而使授信人的预期收益与实际收益发生偏离的可能性它是金融风险的主要类型。巴塞尔协议定义金融风险类型:市场风险、作业风险、信用风险。信用风险A...
一 传统优化算法机器学习中模型性能的好坏往往与超参数(如batch size,filter size等)有密切的关系。最开始为了找到一个好的超参数,通常都是靠人工试错的方式找到"最优"超参数。但是这种方式效率太慢,所以相继提出了网格搜索(Grid Search, GS) 和 随机搜索(Random Search,RS)。但是GS和RS这两种方法总归是盲目地搜索,所以贝叶斯优化(Bayesian O
一个读人工智能的论文网站:Paperswithcodepaperswithcode.com/https://link.zhihu.com/?target=https%3A//paperswithcode.com/类别丰富,涵盖了各个人工智能的方向文章,当然也包括各领域的经典论文
在使用GBDT、RF、Xgboost等树类模型建模时,往往可以通过 feature_importance 来返回特征重要性,各模型输出特征重要性的原理与方法一 计算特征重要性方法首先,目前计算特征重要性计算方法主要有两个方面:1.1 训练过程中计算训练过程中通过记录特征的分裂总次数、总/平均信息增益来对特征重要性进行量化。例如实际工程中我们会用特征在整个GBDT、XgBoost里面......