- @yyyyyybw
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
从刷脸支付、AI绘画,到工厂里的智能质检和能源系统的预测性维护,人工智能正在改变我们的生活和生产方式。通过摄像头获取视觉信息,再结合深度学习算法,机器不仅能“看”,还能“理解”。随着大模型的兴起,NLP 已经从“能听懂关键词”发展到“理解上下文并推理”,这意味着机器正在向真正的“智能助手”迈进。未来,随着AI算法、传感器和5G的加持,机器人将更灵活、更智能,成为工厂里“不可或缺的同事”。,钡铼技术
PyTorch 是一个用于机器学习和深度学习的开源深度学习框架,由 Facebook 于 2016 年发布,其主要实现了自动微分功能,并引入动态计算图使模型建立更加灵活。【pytorch算法入门到进阶教程】【2025】这才是科研人该学的pytorch教程!通俗易懂,完全可以自学,7天带你构建神经网络,解决pytorch框架问题!深度学习|机器学习|人工智能这才是科研人该学的!一口气学完深度学习【T

通俗易懂,完全可以自学,7天带你构建神经网络,解决pytorch框架问题!PyTorch 的语法与 NumPy 高度兼容,且天然支持 Python 生态工具(如 Jupyter Notebook),降低学习门槛。PyTorch的应用场景是深度学习领域,包括计算机视觉、自然语言处理、生成式模型等多个方面。传统框架(如 TensorFlow)使用静态计算图,需预先定义完整模型结构,调试困难。PyTor

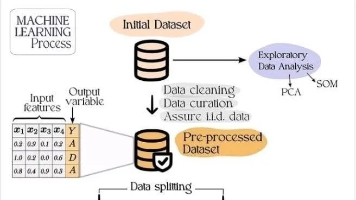
机器学习算法是 AI 系统执行任务的规则或流程,通过对数据的分析学习,自动挖掘规律和模式,用于预测、分类、聚类等任务,实现智能化数据分析处理。依据输入数据(标记或未标记),对数据模式评估,用于预测或分类。比如判断邮件是否为垃圾邮件(分类),预测股票价格(预测)。评估模型预测结果。与已知示例对比,衡量模型准确性,如计算预测值和真实值的差值。若模型与训练数据拟合欠佳,调整权重缩小已知样本与模型估计的差

✅基础且实用的CV方向,从手机AI到工业机器人都离不开它,就业与科研都不愁。前景:短视频时代的必备技术,需求量大而且门槛高,懂这个的人才不愁找工作。✅大语言模型带火了多模态,现在正是风口,学好了不管是就业还是读博都吃香。✅医学自动驾驶都需要它,应用场景多,而且还在不断拓展中,很有发展空间。✅医疗AI最热门的方向之一,专业性强,钱景好,而且还在帮助他人。✅元yz最需要的就是它,VR/AR火了它就火,
机器学习项目的难度分类通常取决于问题的复杂性、数据处理的难度、算法的深度以及部署的规模。
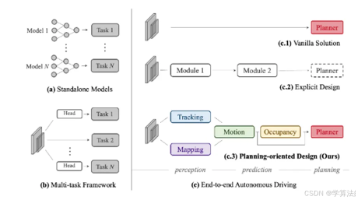
端到端自动驾驶基本流程:(1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型;(2)由数据驱动的方式来解决长尾问题,取代rule-based的结构。优点:(1)直接输出控车指令,避免信息损失;(2)具备零样本学习能力,更好解决OOD问题;(3)数据驱动方式解决自动驾驶长尾问题;(4)避免上下游模块误差的过度传导;(5)模型集成统一,提升计算效率。● 开环指标○ L2误差○ 碰撞
这两年人工智能爆火,为了提升学术竞争力,由Anthony Goldbloom和Ben Hamner创立于2010年,,2017年被Google收购。从公司的角度来讲,可以提供一些数据,进而提出一个实际需要解决的问题;从参赛者的角度来讲,他们将组队参与项目,针对其中一个问题提出解决方案,最终由公司选出的最佳方案可以获得5K-10K美金的奖金。
如何提升论文创新性和实验效率?猜你想要“即插即用模块”。现在这类能“无缝集成”、“快速启用”的模块已经成了深度学习论文写作的必备工具。一方面因为其模块化设计和标准化接口,可以简化开发流程,方便我们结合具体任务选择合适的模块,快速验证创新点。另一方面,“即插即涨点”的特性也能提升模型性能,增强论文竞争力。而且更重要的是,这些模块的复现代码和轻量化设计,大幅降低了技术门槛与资源消耗。

大模型,顾名思义,指的是那些在训练过程中需要海量数据、超强计算能力和大量参数的人工智能模型。这些模型具有惊人的规模、庞大的参数数量以及复杂的算法结构,使其能够处理各种复杂的任务和数据。这些“巨型”模型能从海量的信息中提取出深层次的规律,进而进行高度复杂的任务,如自然语言理解、图像生成、自动推理、机器翻译等。