




- @yuanlulu
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在看李航的《统计学习方法》的时候没有结合代码,总感觉比较虚。github上有个中国学生开源的机器学习python实现,比较全面,文档也不错 https://github.com/lawlite19/MachineLearning_Python 可以动手敲一遍,加深理解。目录摘抄如下:机器学习算法Python实现一、线性回归1、代价函数2、梯度下降算法3...
按照官方的说明,该方案是一个集成了俩小模型的方案,就是不知道俩小模型的侧重点。总的来说,开源这么一个可用的RGB单帧模型,很值得欣赏。

假设"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"被下载到了/mnt/llm_deploy/目录下,则模型的绝对路径是/mnt/llm_deploy/DeepSeek-R1-Distill-Qwen-32B,后面部署会用到这个目录。上面映射了目录/mnt/llm_deploy/到容器内部的/home/llm_deploy,则容器内看到的模型目录是/home/l

概述本人断断续续花费了两周时间,在某国产ARM64+linux环境的服务器上,使用docker容器安装成功了公司深度学习项目所需的环境。中间过程坎坷,在此结文以记,希望能对他人有所帮助,少踩坑。目前成功搭建的环境如下:aarch64 docker容器,ubuntu18.04, python2, opencv3.3, dlib19.15, tensorflow1.5, sklearn。上...
概述OpenVINO是intel的深度学习工具框架,本质是一个支持intel各种硬件(CPU、集显、FPGA和Movidius VPU)的推理机。这个工具本身不做训练,但是可以把其它深度学习框架(如 Caffe, TensorFlow, MXNet)训练的模型文件转化为自己支持的格式。所以OpenVINO分为两部分(github上源码也分为这么两个目录):Inference Engine...
批归一化(BN)的缺点BN 需要用到足够大的批大小(例如,每个工作站采用 32 的批量大小)。一个小批量会导致估算批统计不准确,减小 BN 的批大小会极大地增加模型错误率。加大批大小又会导致内存不够用。归一化的分类BN,LN,IN,GN从学术化上解释差异:BatchNorm:batch方向做归一化,算N*H*W的均值LayerNorm:channel方向做归一化,算C*H*W的均值...
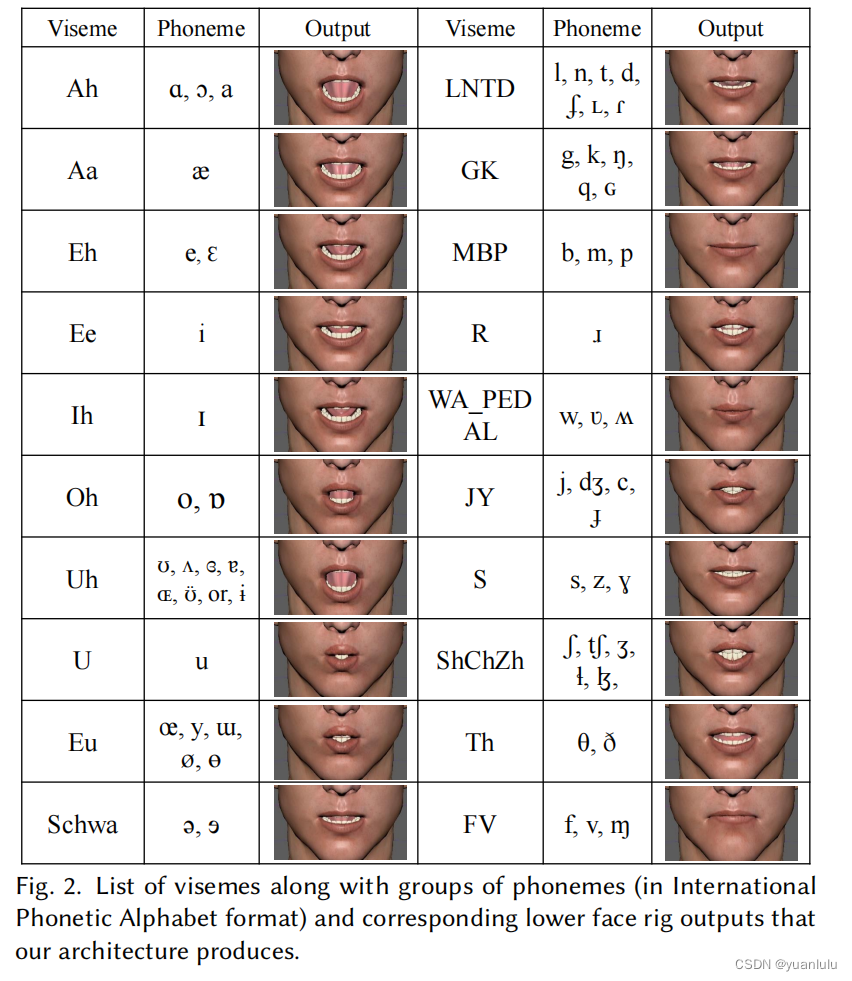
看官网资料,他们主要是做口型动画的,他们的主要方法和概念在论文《》里有介绍。他们通过观察发现,人们发音时的动作有两个重要维度,一是下巴骨骼的运动,二是嘴部肌肉的运动。而不同的说话"风格",可以通过调整这两个维度从而捕捉到更有表达力的口型。比如同一个人用不同的情绪来发同一个音素,其口型差距巨大。不同的发音方法对应的嘴唇宽度和下巴位移量都不一样。在JALI的坐标轴中,五种风格的发音分布如下。其横坐标是
大模型的基本特征就是大,单机单卡部署会很慢,甚至显存不够用。毕竟不是谁都有H100/A100, 能有个3090就不错了。目前已经有不少框架支持了大模型的分布式部署,可以并行的提高推理速度。不光可以单机多卡,还可以多机多卡。

vLLM是一个快速且易于使用的库,用于LLM(大型语言模型)推理和服务。通过PagedAttention技术,vLLM可以有效地管理注意力键和值内存,降低内存占用和提高计算效率。vLLM能够将多个传入的请求进行连续批处理,从而提高整体处理速度。

"content": "你是我的小助理"},"content": "告诉我你是谁"],}'
