- @wwwwwww31311
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以下问题都可以直接从chatgpt获取标准答案,或参考相关知识点大纲。
感知机通过监督学习从已标注邮件中学习一组特征权重,找到能区分垃圾邮件和正常邮件的线性边界;那些在垃圾邮件中更具有区分性的特征,如“免费”“中奖”“链接”等,通常会被赋予较高的正向权重,从而使包含这些特征的新邮件更容易被判为垃圾邮件决策树6. 定义损失函数和优化方法损失函数:衡量模型预测与真实标签之间差距的函数回归常用 MSE(均方误差)二分类常用交叉熵(Binary Cross Entropy)优
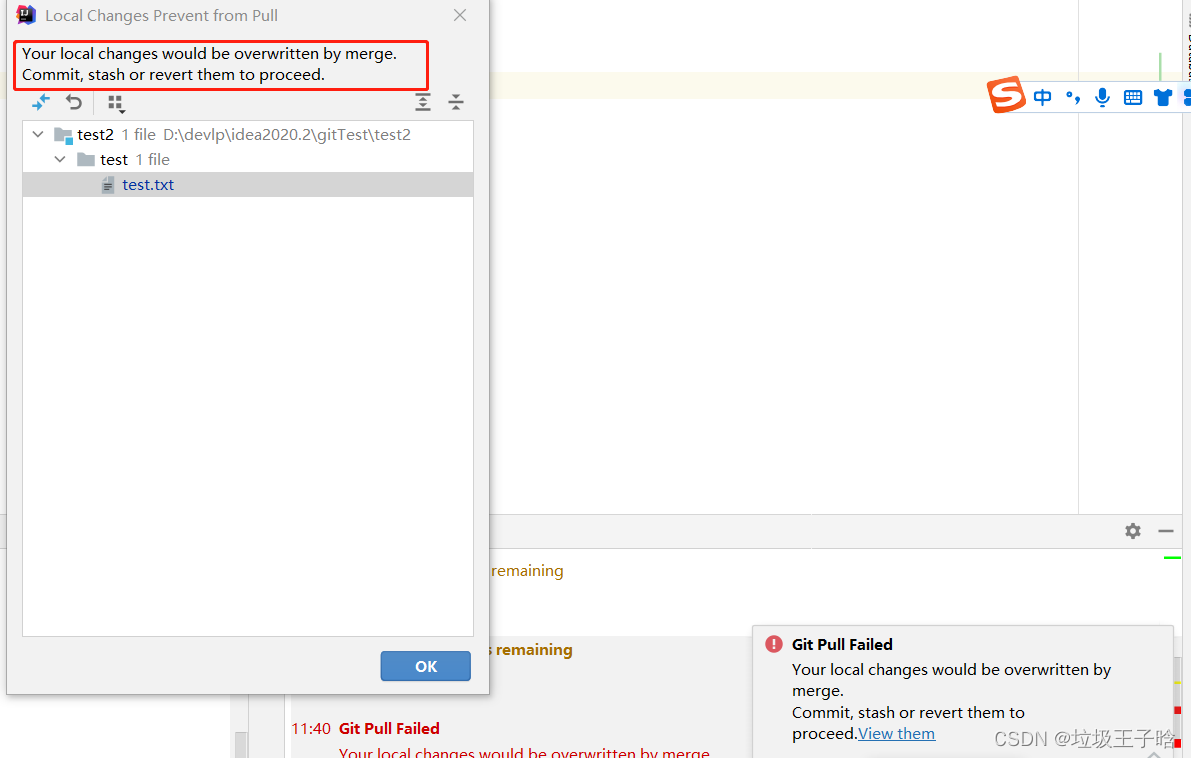
1、流程对比pull->commit->push #在本地修改与远程代码无冲突的情况下,优先使用commit->pull->push #在本地修改与远程代码有冲突的情况下,优先使用2、怎么去确定是否有冲突呢?一般我们在合作开发一个项目的过程中,都会有分工有时会两个人同时修改一个类,那你俩就大概率会在这个类里面产生冲突;有时整个类都是你自己在开发。如果都是自己在开发的类自然无
备注:一开始粗心了,有效接待字段搞错了,导致数据对不上(把sessionHumanValidRecep和sessionHumanSelfValidRecep搞混了),追代码中字段sessionHumanValidRecep,,看看有没有字段或者后续的查询,弄了半天发现是字段选错了...

首先,在配置中检查要读取的分支是否正确,从2020年几月份开始,github上的master分支变为了mian分支。因此yml中读取分支的配置应该是:label: main其次,如果yml使用的是uri: git@github.com:***/springcloud-config.git这种ssh方式连接的话,需要进行其他的配置,因此我放弃了这种方式进行配置,而采用http/https方式进行配置
前言:我们整个es的学习全程都在拿es和mysql做对比,今天我们再比较下二者的速度,为啥es比数据库mysql查询快那么多?首先ES是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,而正巧,mysql最不擅长的就是全文检索,分析如下从es读数据的流程在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已
前言ES基础概念和ES的基础命令一样,我们都会参考mysql的概念,但es集群其实和kafka非常相似,我们会参考kafka来进行对比ES基础概念:Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存
今天pom中突然报错Plugin ‘org.springframework.boot:spring-boot-maven-plugin:‘ not found,回想之前的经验,这种情况下,往往都是添加上版本号就能解决这种情况要么是idea抽风,要么因为在仓库中的spring-boot-maven-plugin文件夹下有至少两个版本的spring-boot-maven-plugin,那么顺着这种思路
首先,在配置中检查要读取的分支是否正确,从2020年几月份开始,github上的master分支变为了mian分支。因此yml中读取分支的配置应该是:label: main其次,如果yml使用的是uri: git@github.com:***/springcloud-config.git这种ssh方式连接的话,需要进行其他的配置,因此我放弃了这种方式进行配置,而采用http/https方式进行配置
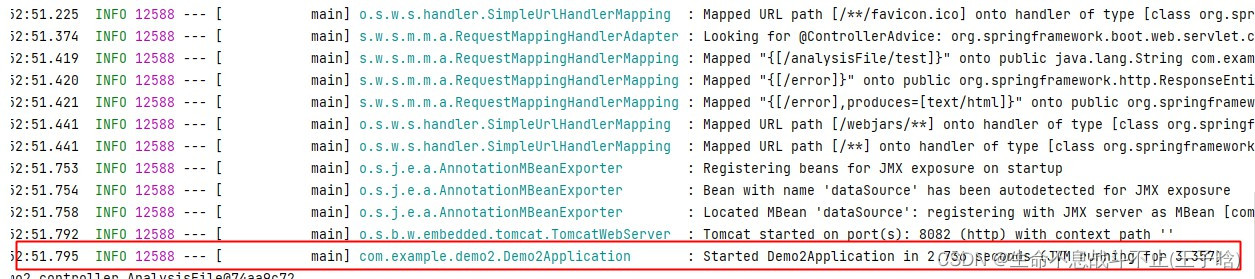
看到这条日志才能判定项目是启动成功的。