
写文章




- @weixin_74181752
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
Reinforcement Learning for VLA(强化学习+VLA)
本文探讨了强化学习(RL)与视觉-语言-动作(VLA)模型结合的机器人操控系统。

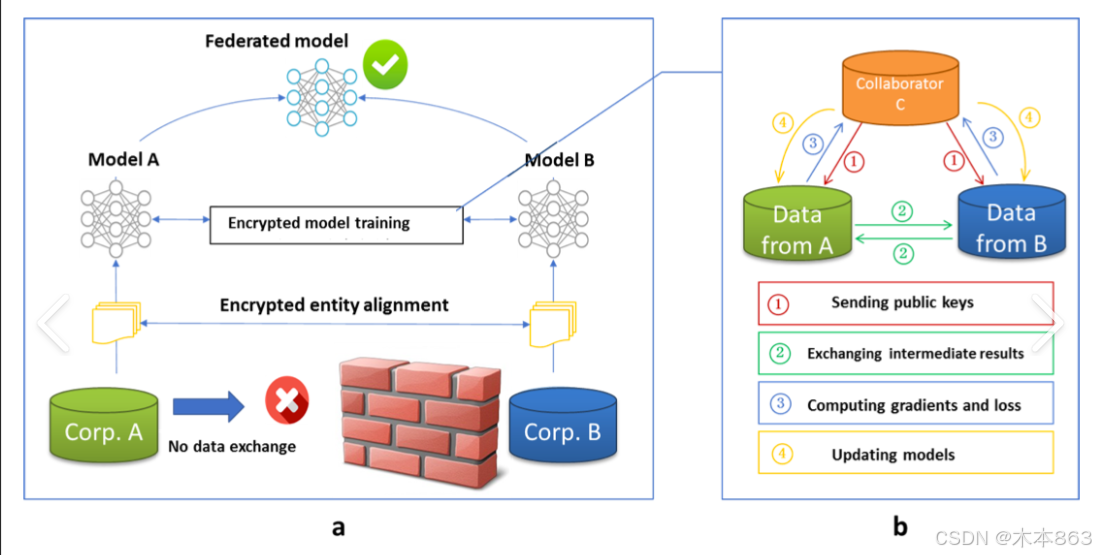
联邦学习研究方向及论文推荐(二)
第二篇联邦学习论文推荐。
【记录】为ubuntu系统安装显卡驱动后掉网卡驱动
分析解决Ubuntu系统安装NVIDIA显卡驱动后可能出现网卡驱动丢失问题

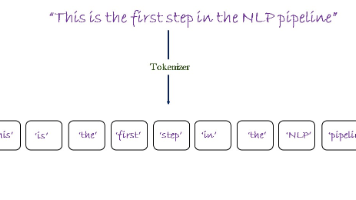
大模型的分词器——算法及示例
分词是自然语言处理的基础技术,将文本分割为离散单元(如单词、子词或字符)。主流方法包括词级、字符级和子词分词,其中子词分词(如BPE、WordPiece)通过拆分单词平衡了词汇表大小与序列长度。BPE通过频次合并字符对构建词汇表,WordPiece则基于互信息分数优化合并策略。这些方法解决了未知词汇问题,提升了模型效率,广泛应用于GPT、BERT等大型语言模型。分词器的选择需考虑任务需求(单语言/
Reinforcement Learning for VLA(强化学习+VLA)
本文探讨了强化学习(RL)与视觉-语言-动作(VLA)模型结合的机器人操控系统。

到底了