




- @weixin_54171657
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
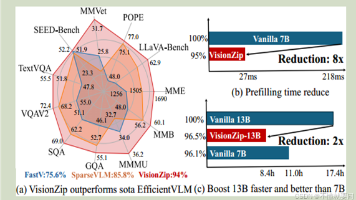
《VisionZip:视觉语言模型中的高效视觉标记压缩方法》针对现有视觉语言模型(VLMs)存在的视觉标记冗余问题,提出了一种创新解决方案。研究发现,传统VLMs使用长序列视觉标记会导致计算成本高昂,且大量标记注意力权重趋近于零,存在显著冗余。VisionZip通过两阶段处理(保留主导标记+合并次要标记),在仅保留10%标记的情况下实现95%的原模型性能,并将LLaVA-NeXT模型的预填充时间减
GPT2主要探讨了语言模型在没有明确监督的情况下,通过在大规模网页文本数据集(WebText)上进行训练,能够学习执行多种自然语言处理任务的能力。研究团队通过实验展示了语言模型在问答、机器翻译、阅读理解等任务上的表现,并分析了模型容量对性能的影响。背景知识自然语言处理任务:通常需要通过监督学习在特定数据集上进行训练,如问答、机器翻译、阅读理解和文本摘要等。语言模型:通过预测文本序列中的下一个词来学

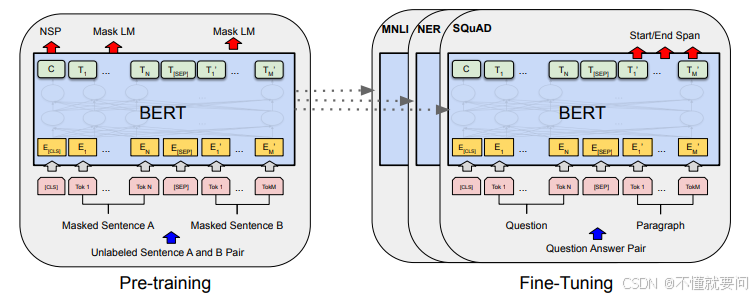
简要介绍BERT模型的基础知识
初步了解Flux-1-dev模型的代码

GPT1介绍了一种通过生成式预训练(Generative Pre-Training)来提升语言理解能力的方法。这种方法首先在一个大型的未标注文本语料库上进行语言模型的预训练,然后针对具体的任务进行判别式微调(discriminative fine-tuning)。文章详细阐述了这种方法的动机、相关工作、框架、实验结果以及分析。背景知识与研究动机自然语言理解(NLU)涉及多种任务,如文本蕴含、问答、
GPT-3 是 GPT-2 的显著升级版本,通过增加模型规模、改进训练数据和方法,以及增强少样本学习能力,GPT-3 在多种自然语言处理任务上表现出色,展示了大型语言模型在通用性和适应性方面的巨大潜力。尽管 GPT-3 仍有一些局限性,但其在文本生成和理解方面的进步为未来的研究和应用提供了新的方向。

GPT2主要探讨了语言模型在没有明确监督的情况下,通过在大规模网页文本数据集(WebText)上进行训练,能够学习执行多种自然语言处理任务的能力。研究团队通过实验展示了语言模型在问答、机器翻译、阅读理解等任务上的表现,并分析了模型容量对性能的影响。背景知识自然语言处理任务:通常需要通过监督学习在特定数据集上进行训练,如问答、机器翻译、阅读理解和文本摘要等。语言模型:通过预测文本序列中的下一个词来学
datasets库入门使用

这张图可以清晰明了的显示EfficientNet 的卓越表现,一句话总结:更小的模型、更快的速度、更好的效果。
