




- @weixin_53547097
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
下载hadoop 2.X,下载JDK1.8,安装CentOS7镜像,这里我自己是用VM虚拟机的环境来搭建三台集群。安装Linux系统并停掉防火墙,禁止SeLinux,配置时间同步定时刷新集群系统时间通过VM直接克隆出另外两台机器,配置IP地址,确保三台机器相互之间能ping通,能联网。然后增加专门用于hadoop的hadoop用户,为root用户和hadoop都配置ssh免秘钥登录首先修改/etc

本文章使用VMware虚拟机平台搭载CentOS-7-x86_64-DVD-2009镜像文件进行Hadoop-3.1.3环境搭建。
使用 Node.js 的流行后端框架包括 Express.js、Meteor.js、Nest.js 和 Hapi.js。如果您的项目使用不同版本的 Node.js,那么 NVM 就是适合您的工具。由于 JavaScript 在编程中的广泛流行,Node.js 已成为软件开发和运行 JavaScript 应用程序的服务器的 Linux 管理中的重要组件。使用 Node Version Manager

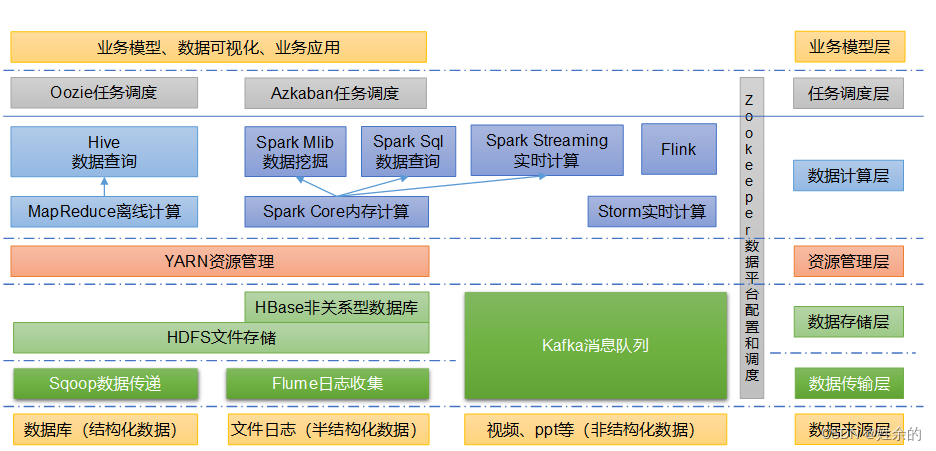
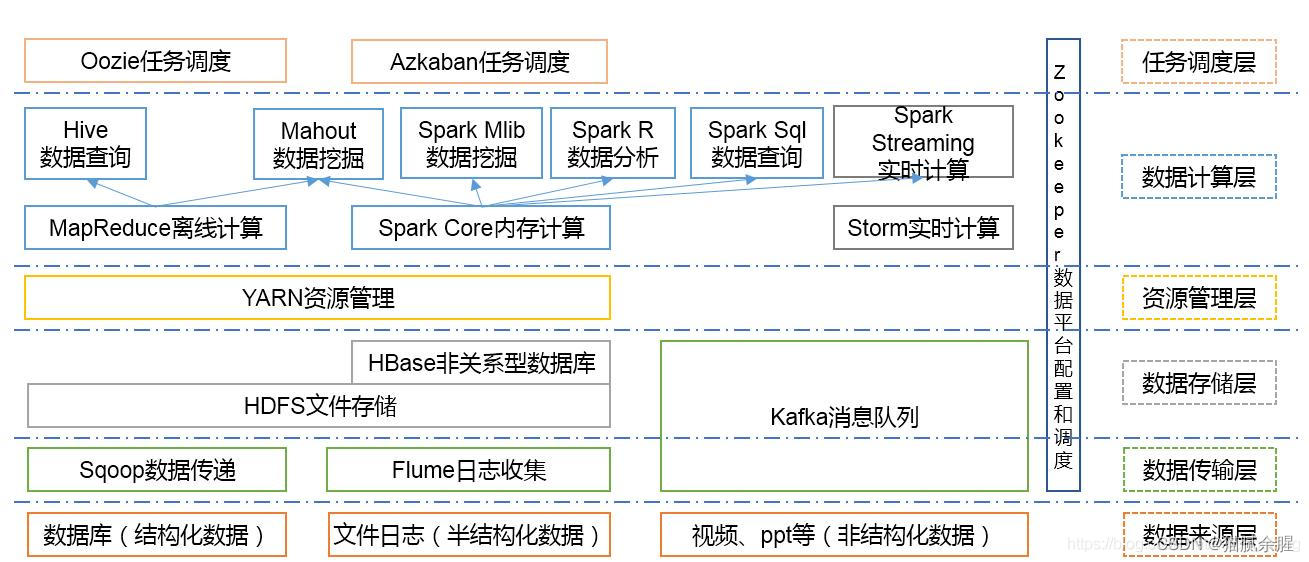
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1)什么是序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。反序列化就是将收到字节序列(或其他数据传输协议

Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。2.分布式文件系统:HDFS1.HDFS架构2.简介指被设计成适合运行在通用硬件上的分布式文件系统。3.特点HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序
'''功能:输出200-500的素数作者:Sherry时间:2021.11.11'''from math import sqrtfor n in range(200, 501):is_price_number = True# 假设永真for i in range(2, int(sqrt(n) + 1)):#利用sqrt来减少计算机的工作量if n % i == 0:is_price_number