
大数据入门-大数据技术概述(一)
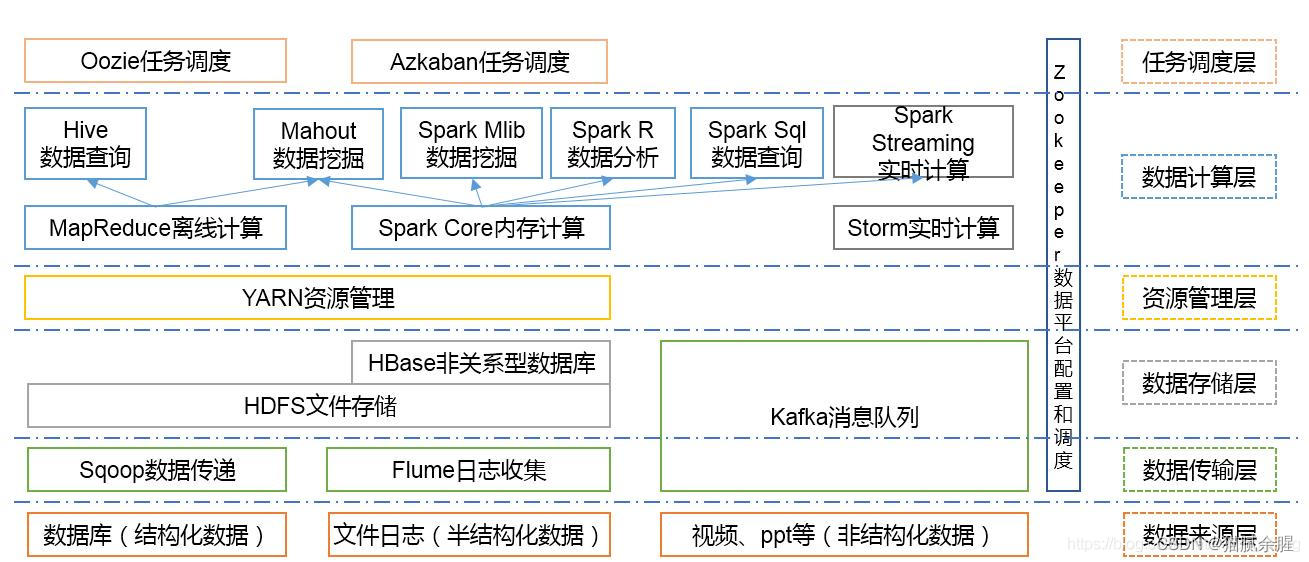
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。2.分布式文件系统:HDFS1.HDFS架构2.简介指被设计成适合运行在通用硬件上的分布式文件系统。3.特点HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序
大数据入门系列文章
- 大数据入门-大数据是什么
一、概念
大数据技术是指在构架大数据平台的时候需要的技术。包含存储系统,数据库,数据仓库,资源调度,查询引擎,实时框架等。下面以我目前所了解到的一些技术做简要介绍。目前之介绍简单概念。
二、技术详解
1.基础架构:Hadoop
1.架构

2.简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
2.分布式文件系统:HDFS
1.HDFS架构

2.简介
指被设计成适合运行在通用硬件上的分布式文件系统。
3.特点
HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
3.数据仓库:Hive
1.架构
2.简介
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
3.特点
执行过程走MapReduce比较慢,处理规模大,可扩展性高,加载模式为读时模式。后面就MapReduce会做专门的解释。
4.存储引擎:Kudu
1.架构
2.简介
Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu支持水平扩展,使用Raft协议进行一致性保证,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合紧密。
3.特点
支持随机读写,支持OLAP 分析,太多列查询时性能下降,跟关系型数据有点类似。其存储文件不在HDFS上面,有自己的存储文件系统。
5.分布式数据库:HBase
1.架构
2.简介
HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
3.特点
高可靠、高性能、面向列、可伸缩。
6.实时框架:Flink
1.架构
2.简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
3.特点
流处理特性、API支持、Libraries支持、整合支持。
三、其他
以上就是我目前涉及到的部分技术,下一篇出Zookpeer、Yarn、Spark、Impala、Kafka、Flume。
————————————————
版权声明:本文为CSDN博主「水坚石青」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/helongqiang/article/details/119282811
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)