




- @weixin_52550626
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何接入飞书机器人的完整配置流程:1)在飞书开放平台创建机器人并获取appid/appsecret;2)配置权限管理并复制指定权限代码;3)启用飞书插件和添加渠道;4)设置访问策略(配对/开放/白名单模式);5)配置事件回调并发布机器人;6)测试私聊功能后开启群聊配置。重点包括权限设置、访问策略选择(默认使用配对模式)以及群聊的mention功能配置。
Clawdbot是一款开源的、本地优先(Local-First)的个人 AI 助手。它的核心理念是让 AI 真正“驻留”在你的设备或私有服务器上,并通过你日常使用的通讯软件(如 WhatsApp, Telegram, Discord, Slack 等)为你提供服务。与完全依赖云端 SaaS 服务的 AI 助手不同,Clawdbot 强调数据的掌控权和本地执行能力。它不仅能聊天,还能通过“工具”控制

MCP与Skills的本质区别在于应用场景和技术架构:MCP是AI连接外部系统的标准化协议,适用于远程API和对外服务,但存在上下文消耗大的问题;Skills则是编码内部工作流程的轻量级解决方案,采用渐进式披露和脚本执行机制,显著降低上下文负担。最佳实践是两者结合使用 - Skills处理本地流程和专业知识,MCP负责远程连接,但随着Skills生态成熟,MCP将主要服务于跨网络连接场景。开发者应
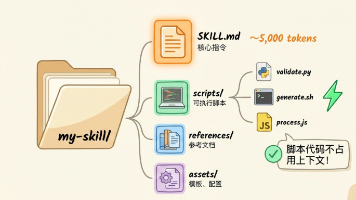
MCP与Skills的本质区别在于应用场景和技术架构:MCP是AI连接外部系统的标准化协议,适用于远程API和对外服务,但存在上下文消耗大的问题;Skills则是编码内部工作流程的轻量级解决方案,采用渐进式披露和脚本执行机制,显著降低上下文负担。最佳实践是两者结合使用 - Skills处理本地流程和专业知识,MCP负责远程连接,但随着Skills生态成熟,MCP将主要服务于跨网络连接场景。开发者应
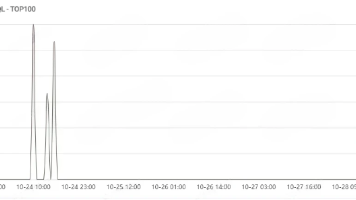
本文通过一个线上慢SQL案例,分析了Join查询和Orderby排序的工作原理。案例中,一个包含3000行和70000行数据的表进行Left Join时,MySQL选择了Block Nested-Loop算法,导致被驱动表多次全表扫描,性能低下。通过Explain和Optimizer_trace工具分析发现,虽然执行引擎预估排序开销最大,但实际瓶颈在于Join算法选择不当。最终通过为被驱动表添加索
Clawdbot是一款开源的、本地优先(Local-First)的个人 AI 助手。它的核心理念是让 AI 真正“驻留”在你的设备或私有服务器上,并通过你日常使用的通讯软件(如 WhatsApp, Telegram, Discord, Slack 等)为你提供服务。与完全依赖云端 SaaS 服务的 AI 助手不同,Clawdbot 强调数据的掌控权和本地执行能力。它不仅能聊天,还能通过“工具”控制
MCP与Skills的本质区别在于应用场景和技术架构:MCP是AI连接外部系统的标准化协议,适用于远程API和对外服务,但存在上下文消耗大的问题;Skills则是编码内部工作流程的轻量级解决方案,采用渐进式披露和脚本执行机制,显著降低上下文负担。最佳实践是两者结合使用 - Skills处理本地流程和专业知识,MCP负责远程连接,但随着Skills生态成熟,MCP将主要服务于跨网络连接场景。开发者应
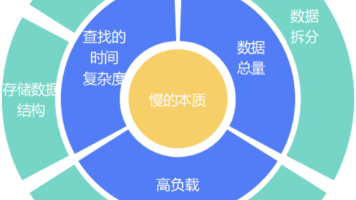
本文针对数据库性能优化,总结了八大方案,涵盖减少数据量、用空间换性能、选择合适的存储系统三大方向。从存储结构和存储系统层面出发,详细介绍了数据序列化存储、数据归档、中间表生成、分库分表等减少数据量的方法,以及分布式缓存、一主多从等用空间换性能的方案,最后探讨了CQRS和替换存储系统等优化手段。文章强调要根据业务场景选择合适方案,指出数据同步会带来一致性问题,适合读多写少场景,并提醒没有放之四海而皆
应用启动我们创建了一个启动类,其中初始化了一个基于注解的应用上下文。这个上下文根据类配置了 Spring 容器。Java配置在类中,我们使用@Bean注解定义了一个名为的 bean。这确保了类的实例被 Spring 容器管理。资源管理类模拟了数据库的连接和断开过程。当这个类被实例化时,它模拟建立了一个数据库连接。然后,当这个 bean 被销毁时(由于上下文的关闭),它的destroy()方法被调用

Spring框架中的HierarchicalBeanFactory接口扩展了BeanFactory,支持父子容器层次结构,允许子容器访问父容器的Bean定义。主要提供getParentBeanFactory()获取父容器和containsLocalBean()检查本地Bean的方法。核心实现类DefaultListableBeanFactory支持依赖注入、生命周期管理等。通过父子容器实践展示了B
