




- @weixin_51607793
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
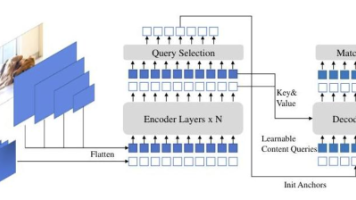
本文将带读者了解目标检测模型 Grounding DINO 和 DINO-X 的始祖 DINO。该模型不仅在端到端目标检测方面取得了重大突破,在 COCO 基准测试上实现了当时最先进的结果,还显著提升了训练效率,使类 DETR 模型更适用于实际应用。DINO 模型的成功证明了基于 Transformer 的目标检测方法的可行性,还开辟了新的研究方向。随着计算资源的增加和数据规模的扩大,DINO 模
DINO-X代表了开放世界目标检测和理解的重大进步。通过将多种感知任务统一到单个模型中并支持灵活的提示机制,它为全面的图像分析提供了一个多功能框架。该模型处理长尾分布的能力以及在罕见物体类别上的强大性能,解决了先前方法的重要局限性。此外,优化的Edge版本的开发使这项技术在资源受限设备上的实际应用更加普及,让先进的计算机视觉能力不再局限于高性能服务器,而是可以融入我们的日常设备。

Grounding DINO 推动了开集目标检测的重大进步,它将基于 Transformer 的DINO检测架构与基础预训练(Grounded Pre-Training)技术的优势相结合。这种融合使模型能够通过自然语言输入检测任意指定的物体,无论是简单的类别名称还是复杂的指代表达。本文将带领读者,了解 DINO 家族首个开集目标检测模型 Grounding DINO。
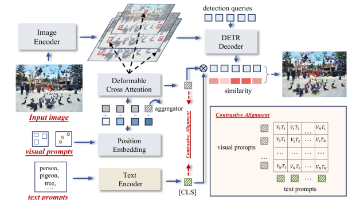
本文是《探访 T-Rex2 家族》系列内容的第 1 篇,旨在通过深入浅出的形式为读者介绍使用文本-视觉提示的通用目标检测模型 T-Rex2,并为读者解答:为什么我们需要 T-Rex2?什么是 T-Rex2?它的优势和局限性是什么?它有什么样的应用场景。
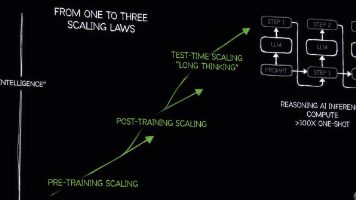
过去十年,视觉 AI 经历了从简单的图像识别,到复杂的图像生成,再到当前的具身交互的跨越式发展。当前,视觉 AI 正处于一个关键的转折点。随着扩散模型、多模态大模型的突破,以及包括 NVIDIA Blackwell 架构等新一代计算基础设施的支持,视觉 AI 正迈向更广阔的应用前景。本文将深入探讨视觉模型的技术演进路径以及前沿应用场景,为读者勾勒出视觉 AI 的未来图景。
生动有趣地讲解“面向多实例指代任务的视觉语言模型” DINO-XSeek

本文基于行业合作伙伴在数据集标注、模型训练等工作流程中使用不同数据标注工具的反馈,总结出 2025 年迄今为止最好用的 5 款数据标注工具,并将对比这些工具的核心功能,帮助用户找到最合适的选择。
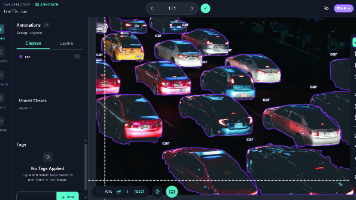
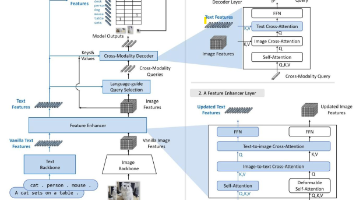
IDEA-CVR 发布新一代面向多实例指代任务的视觉语言模型 DINO-XSeek,该模型通过融合DINO-X 统一视觉模型基座与多模态大语言模型,在保持精确感知能力的同时,拥有多模态大语言模型强大的推理和理解能力,突破了传统视觉模型对自然语言理解的浅层限制,实现从词汇到语法,再到指代逻辑的多层次理解。

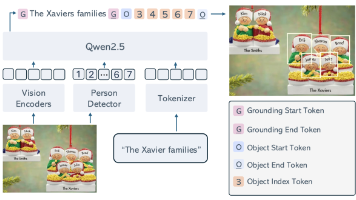
尽管 DINO-X 在物体检测领域取得了显著的进展,但目前包括其在内的目标检测模型基于自然语言描述来精确识别特定个体的能力——即所谓“指代表达理解”依然存在相当的不足。为了提升目标检测模型在 REC 领域的能力,研究人员决定寻找一个被广泛应用的场景——人——作为突破点,以此试验并探讨目标检测模型未来的 REC 改进方向,并提出了 DINO-XSeek 的前身 RexSeek。
本文将带读者了解目标检测模型 Grounding DINO 和 DINO-X 的始祖 DINO。该模型不仅在端到端目标检测方面取得了重大突破,在 COCO 基准测试上实现了当时最先进的结果,还显著提升了训练效率,使类 DETR 模型更适用于实际应用。DINO 模型的成功证明了基于 Transformer 的目标检测方法的可行性,还开辟了新的研究方向。随着计算资源的增加和数据规模的扩大,DINO 模