




- @weixin_51306020
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
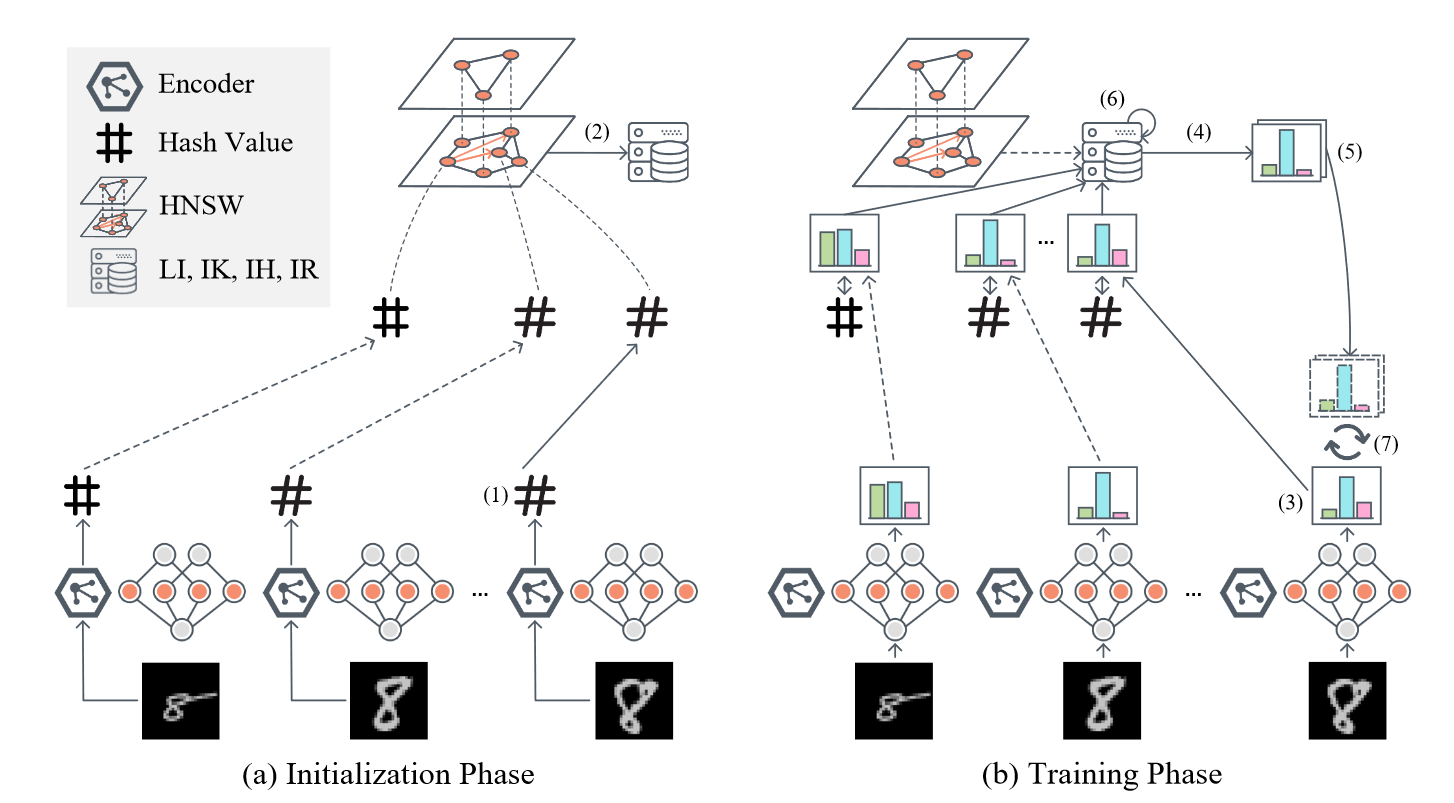
现有的PFL体系结构不能在系统性能(准确性)、资源效率(通信效率)和不依赖公共数据集之间实现良好的权衡,即便LIA比常用的PIA有着显著减少的通信负担和容忍异构模型训练的优势。如何设计个性化的联邦学习,在训练过程中只允许Logits传输,而不需公共数据集,同时优于基于class粒度Logits交互的体系结构?本文提出了FedCache,它是第一个基于 Sample-grained Logits 交
知识蒸馏(Knowledge Distillation)是一种教师-学生(Teacher-Student)训练结构,通常是已训练好的教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识. 它可以以 轻微的性能损失为代价将复杂教师模型的知识迁移 到简单的学生模型中。分出基于知识蒸馏的模型压缩和模型增 强这两个技术方向。其中的教师模型都是提前训练好的复杂网络. 模型压缩和模型增强都是将教师模型的知
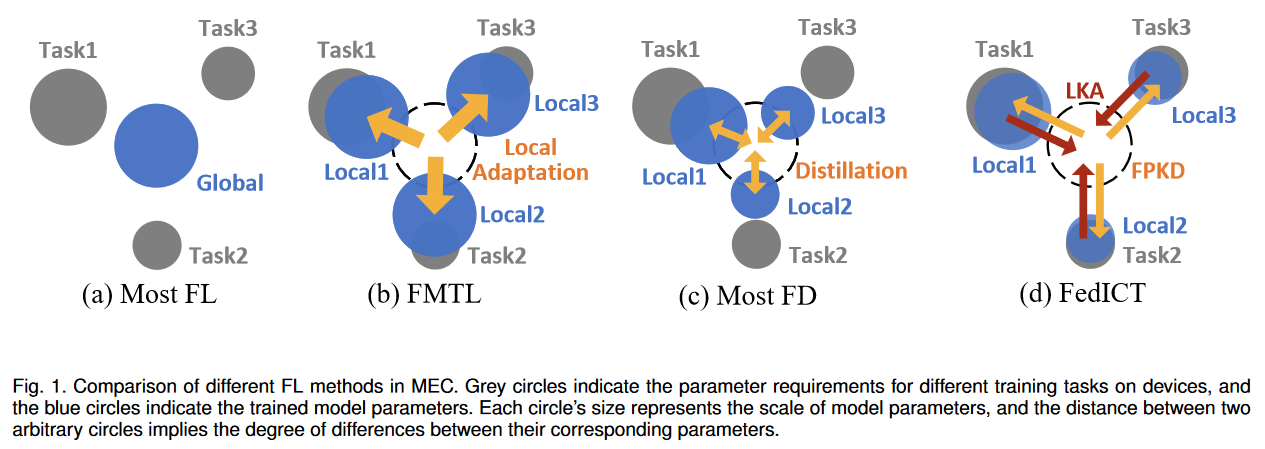
为了在不依赖代理数据集的前提下解决MEC场景下普遍同时存在的个性化模型训练(多任务)、通信负载大、模型不能异质等问题,提出联邦多任务蒸馏框架 FedICT。旨在支持多任务客户端,同时减轻由于客户端本地模型优化方向不同而产生的客户端漂移。FedICT由两部分组成,用于个性化客户端蒸馏的联邦先验知识蒸馏(FPKD)和用于纠正服务器端蒸馏的本地知识调整(LKA)前者基于局部数据分布的先验知识来增强客户端
一种实用的基于平均迭代的联邦学习深度神经网络方法——Federated Averaging算法。它对不平衡和非iid数据分布是稳健的,相较于同步随机梯度下降方法(FedSGD)的通信次数减少10-100倍大大提高了联邦学习得模型效率。......
知识蒸馏(Knowledge Distillation)是一种教师-学生(Teacher-Student)训练结构,通常是已训练好的教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识. 它可以以 轻微的性能损失为代价将复杂教师模型的知识迁移 到简单的学生模型中。分出基于知识蒸馏的模型压缩和模型增 强这两个技术方向。其中的教师模型都是提前训练好的复杂网络. 模型压缩和模型增强都是将教师模型的知
AFL在实际应用中更具有普适性,它能适应于设备不断变化(单个设备自身的硬件性能、添加去除设备、多异构设备协同)的现实场景,并极大地提升联邦学习的训练效率。本文针对异步联邦学习固有的过度拟合、通讯受限、加权聚合等问题,提出了提出TrisaFed,针对三大挑战分别提出应对策略:ICA根据信息型客户端激活策略激活具有丰富信息的客户端、MLU多层更新策略来优化客户端和服务器的交互、时权退减策略(TWF)和
MOCHA主要是为了解决联邦学习中的系统难题和统计难题而提出的联邦学习框架。MTL(多任务学习)通过学习每个节点的独立模型,利用任意的凸损失函数为每个节点训练出独立的权重向量。并且考虑节点模型间的相关性来解决联邦环境中的统计难题,并且提升样本容量,但是目前的MTL难以解决系统难题。在集中环境分布式多任务训练模型CoCoA的基础上进行改进,本文提出联邦多任务学习框架MOCHA,为模型参数W开发有效的
联邦学习相关概念、领域热点、挑战与前景。联邦学习的定义、特点、框架、迭代流程、分类;领域亟待解决的问题;主要研究方向、热点和前景展望。
本文所要解决的问题是异构客户端资源(数据资源:规模过大/小、计算能力:有快有慢、无线通信条件:模型参数传输时长差异 )——延长服务器的聚合、更新步骤,进而降低模型训练的效率。为解决上述问题,作者提出了FedCS框架, 相较于传统的模型,其创新点在于增加了 Resource Request步骤,该步骤可以帮助移动边缘计算(MEC)服务器依据工人上传信息评估其“优劣”。 针对上述三种异构情况,若某工人