




- @weixin_51066144
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
由于你的代码已经是一个独立的 HTML 文件(包含了 CSS 和 JS),不需要复杂的构建过程。我想让 AI 生成一个网页极简任务管理系统,需要一个更完整的提示词,让生成结果更令人印象深刻和有趣。把优化的提示词输入智谱z.ai,在右边测试模型制作的应用,发现bug和缺少的功能,在左边通过对话的形式,让AI不断优化代码。描述:一个具有禅意美学的任务管理工具,专注于简单和高效的任务组织。,访问时不需要
摘要: 本文系统梳理了参数高效微调(PEFT)技术及其演进,针对大模型全量微调的高成本、存储压力及灾难性遗忘等问题,重点对比了Adapter Tuning、Prefix/Prompt Tuning、P-Tuning v1/v2等方法的优劣。核心聚焦LoRA技术,通过低秩分解(ΔW=B·A)实现高效参数更新,结合初始化缩放技巧和动态预算分配(AdaLoRA)提升性能,并介绍QLoRA的4-bit量化
本文深入解析了大模型架构中的关键技术。首先介绍了Llama2的Decoder-Only架构特点,包括预归一化、GQA注意力机制、SwiGLU激活函数和RoPE位置编码。重点探讨了混合专家(MoE)架构,分析了其分治策略、专家网络与门控网络的协同机制,以及通过竞争性损失函数实现"赢家通吃"的原理。文章还对比了GShard的Top-2门控和Switch Transformer的To
摘要:本文介绍了三种主流预训练语言模型的技术特点。BERT采用双向Transformer编码器结构,通过掩码语言模型(MLM)和下一句预测(NSP)任务进行预训练,其输入包含token、位置和片段三种嵌入。GPT基于单向Transformer解码器,以自回归方式生成文本,经历了从微调到零样本学习的演进。T5采用编码器-解码器架构,将所有NLP任务统一为文本转换问题,使用Span Corruptio
本文介绍了注意力机制的类型和Transformer模型结构。注意力机制分为Soft/Hard Attention和Global/Local Attention两类,分别对应连续权重分配和离散选择的不同方式。Transformer的核心结构包括编码器、解码器、位置前馈网络等组件,重点讨论了位置编码的两种实现方式:可学习的绝对位置编码和基于三角函数的固定编码,并比较了绝对与相对位置编码的优劣。文章还涉
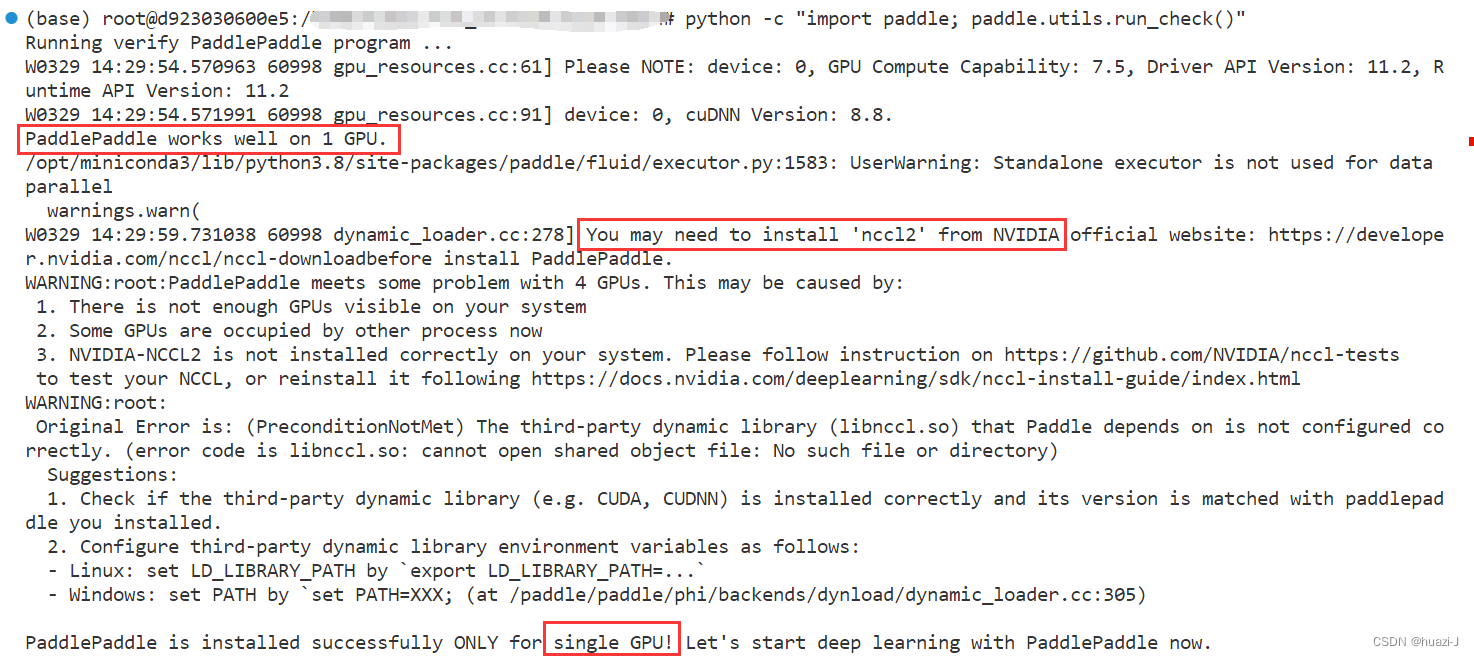
安装nccl
基于RSSI测距的多变定位法1、学习RSSI测距的原理2、学习多边定位法对RSSI定位的实现3、用仿真实现RSSI定位。

windows cuda更新、安装教程