




- @weixin_50873490
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
TEN VAD是由 TEN 团队开发的企业级实时语音活动检测(Voice Activity Detection)系统,于2025年7月正式开源,专门针对低延迟、高精度的语音识别场景设计。核心技术特性帧级检测精度:TEN VAD 采用深度学习架构,实现帧级别的语音活动检测,能够准确识别音频帧中是否包含人类语音并过滤背景噪声。相比传统方法,其检测精度显著提升,在手动标注的测试集上表现优于 WebRTC
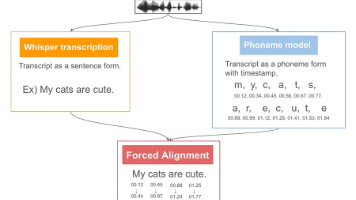
FUNASR是完整的语音识别解决方案,而paraformer-zh-streaming是其核心的中文流式识别模型,两者结合为中文语音识别提供了高效、准确的端到端解决方案。
以下为针对“实时语音转写(标准版)”与“实时语音转写大模型”两者区别及应用场景:问:实时语音转写(标准版)是什么?答:基于深度全序列卷积神经网络,通过 WebSocket 长连接实时将连续音频流转换为文字.问:实时语音转写大模型是什么?答:建立在星火大模型预训练框架上,支持多语种与方言免切识别,能智能断句和补全标点.问:标准版支持哪些音频格式?答:仅支持采样率16 kHz、位深16 bit、pcm
音频分段,滑动窗口输入 -》 特征提取 -》 mel频谱特征 -》 多层次Transformer -》 输出 embeddings(向量化)-》 首次解码后state.tokens=prompt。模型加载 -》 音频样本归一化 -》模型参数设置 -》 编码解码-》 state.tokens文本转化自然语言处理。(如1.8-2.0):对重复更敏感,更容易触发重试,适合处理"优优独播剧场"这类循环输出
一台搭载 Intel Core i7-10700 处理器的服务器具备 8 核心(4 插槽×2 核心)的并行计算能力,基础主频 2.90 GHz,可通过睿频提升至更高频率,配合 64 MiB L3 缓存和每核心 256 KiB L1 及 2 MiB L2 缓存,为多线程应用和虚拟化环境提供稳定高效的执行性能. 最大30G内存。
其在公开基准上取得了3.05%的平均CER,而Paraformer-large(最接近的非流式版本)在WenetSpeech“Test Net”集上的CER为6.74%,可见性能已拉开明显差距。CTC_输出 = ["你", "blank", "你", "好", "blank", "blank", "好", "blank"]CTC_输出 = ["你", "blank", "你", "好", "bla
记得复制api,避免丢失频繁创建。

凭借的CER指标、及,FireRedASR-LLM-L确立了2025年中文ASR领域的新标杆。未来将进一步拓展多语种支持、优化长序列处理,并探索语音-视觉多模态交互应用。采用Encoder-Adapter-LLM架构,参数量8.3B,在多源、多场景(视频、直播、智能助手)均实现24%–40%相对CER下降,兼顾高精度与通用性。适用于对准确率要求极高且可投入计算资源的本地部署场景。基于Attent
其在公开基准上取得了3.05%的平均CER,而Paraformer-large(最接近的非流式版本)在WenetSpeech“Test Net”集上的CER为6.74%,可见性能已拉开明显差距。CTC_输出 = ["你", "blank", "你", "好", "blank", "blank", "好", "blank"]CTC_输出 = ["你", "blank", "你", "好", "bla
凭借的CER指标、及,FireRedASR-LLM-L确立了2025年中文ASR领域的新标杆。未来将进一步拓展多语种支持、优化长序列处理,并探索语音-视觉多模态交互应用。采用Encoder-Adapter-LLM架构,参数量8.3B,在多源、多场景(视频、直播、智能助手)均实现24%–40%相对CER下降,兼顾高精度与通用性。适用于对准确率要求极高且可投入计算资源的本地部署场景。基于Attent