




- @weixin_50164178
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在对分类任务进行预测的时候,通常需要对目标类别进行编码(Encode),这里主要介绍在机器学习中常用的几种编码方式。包括:one-hot编码(独热编码)、标签编码、目标编码、序数编码。

机器学习,无监督学习中的K-Means聚类算法,图解以及实例。

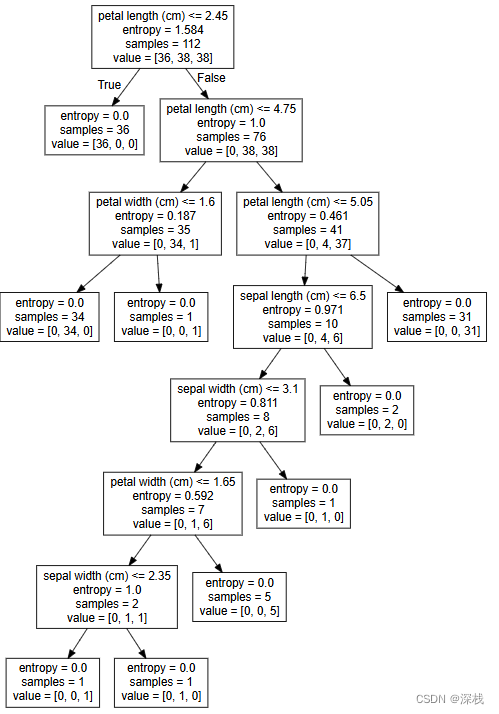
决策树及其可视化,利用天气决定是否打网球为例,来进行训练,并输出可视化文件。
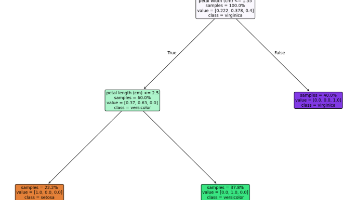
逻辑回归是一个二分类算法,本文主要介绍了逻辑回归流程以及逻辑回归的损失评估,报考精确率和召回率,F1-score,ROC曲线和AUC指标,最后以癌症预测为案例并查看各种评估指标。

决策树是一种基于树结构的分类模型,通过信息熵、信息增益、信息增益率和基尼系数等指标进行特征选择与数据划分。本文以天气数据为例,详细计算了信息熵(H(S)=0.940)、信息增益(天气特征增益最大为0.2467),并针对多值特征问题引入信息增益率(天气特征增益率0.156)。同时演示了基尼系数的计算(初始Gini=0.459),说明不同分裂准则的差异。通过Python代码实现了关键指标的计算,揭示了
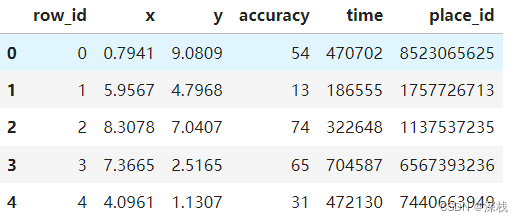
此时正确率较低,是因为筛选了经纬度固定的用户数据,但是我们在处理数据时还新增了一些数据,且过滤掉了次数少于3次的地点,最后,KNN是一个基于距离的算法,对线性关系处理较好。数据通常包括用户ID、签到时间、签到地点的经纬度、位置ID等。其中,row_id表示数据对应的id,在预测时无作用,x,y表示对应的经纬度,而accuracy表示测量进度,time表示时间戳(1970年1月1日起始),place
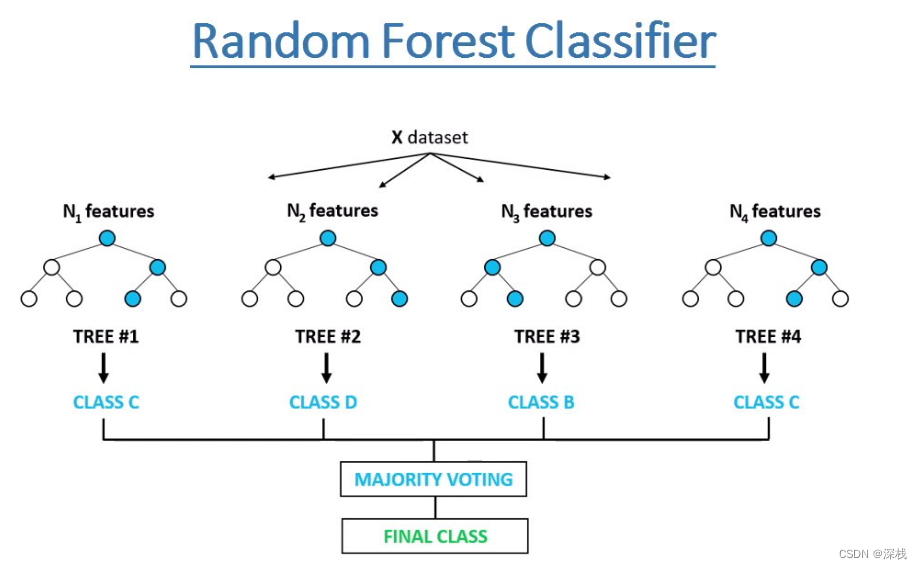
随机森林及其案例
深度学习Pytorch内提供的常用图片增强方法

机器学习,无监督学习中的K-Means聚类算法,图解以及实例。
决策树及其可视化,利用天气决定是否打网球为例,来进行训练,并输出可视化文件。