




- @weixin_49892805
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
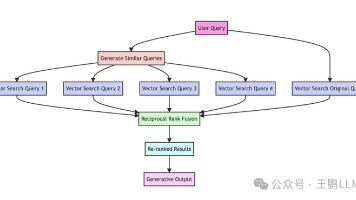
当然这样利用大模型去进行搜索query改写,虽然能够带来更丰富的搜索信息,但是性能上会受到损失,产品上的设计一定要考虑这一点。
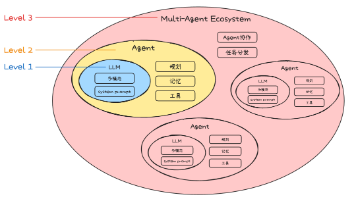
AI Agent 的发展正处于爆发前夜,从最初的 LLM 聊天机器人,到具备规划、记忆、工具调用能力的智能体,再到多 Agent 协作的复杂生态,整个行业正在经历一场范式转变。本文系统梳理了 AI Agent 的核心理念、主流协议(MCP、A2A)、思考框架(CoT、ReAct、Plan-and-Execute),并结合 Golang 生态下的 Eino、tRPC-A2A-Go 等工程化框架,结合
Kimi模型,以其在自然语言处理方面的卓越性能而著称,特别是在情感分析和文本分类任务上表现出色。这得益于其深度学习架构中特殊的注意力机制,能够有效捕捉文本中的关键信息。然而,Kimi在处理长文本时的性能略有下降,因为它更擅长处理。

Python + Excel——飞速处理数据分析与处理

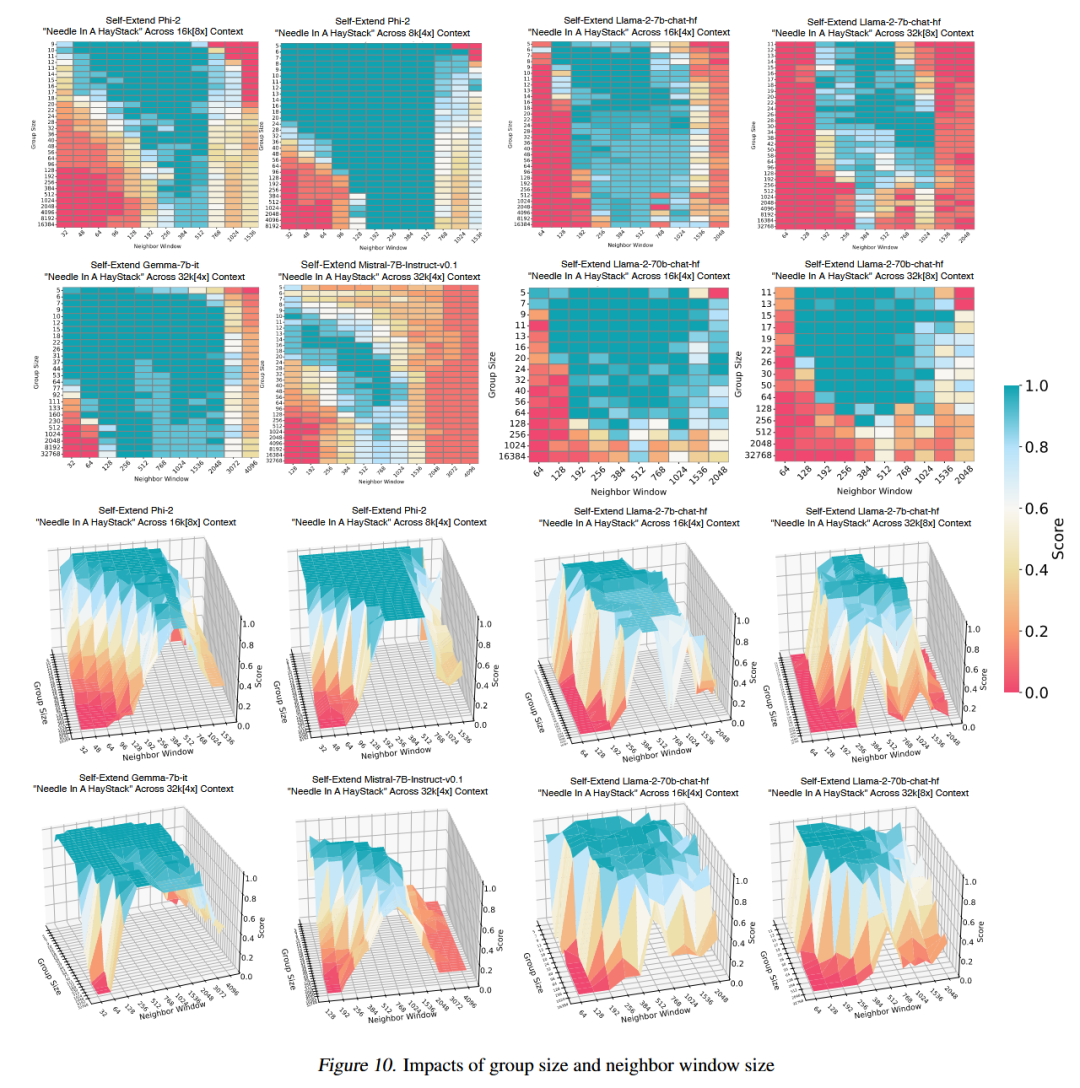
YaRN和SelfExtend分别在微调和推理阶段提供了有效的上下文窗口扩展方案,前者通过优化位置嵌入插值和动态缩放,后者通过双层注意力机制扩展了模型的上下文处理能力。两者在不同应用场景下都表现出色,为大语言模型的长文本处理提供了新的技术路径。
62页PPT,初步看懂人工智能!(非常详细),零基础入门到精通,看这一篇就够了

Python人工智能学习路线(万字长文)
计算机三级证书需要先考二级吗

统计学习、机器学习以及python的学习顺序是什么
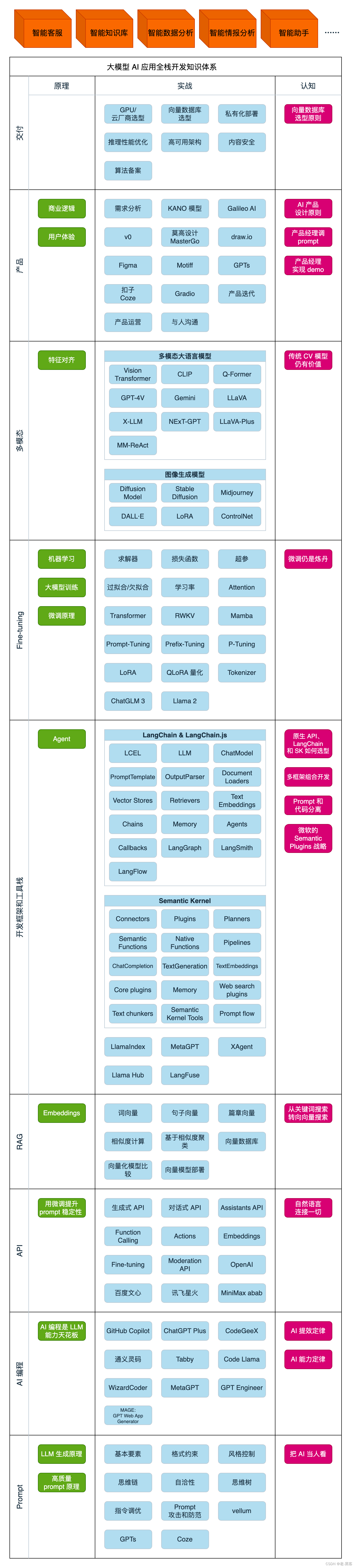
随着 ChatGPT 的爆火,很多机构都开源了自己的大模型,比如清华的 ChatGLM-6B/ChatGLM-10B/ChatGLM-130B,HuggingFace 的 BLOOM-176B。当然还有很多没有开源的,比如 OpenAI 的 ChatGPT/GPT-4,百度的文心一言,谷歌的 PLAM-540B,华为的盘古大模型,阿里的通义千问,等等。
