
写文章




- @weixin_47895059
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization
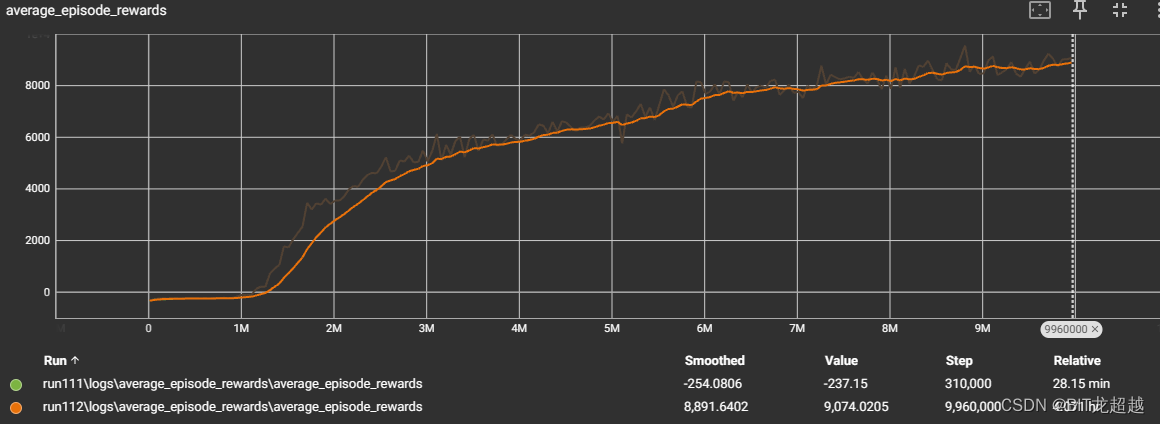
多智能体强化学习mappo算法实践,含pytorch代码

机器学习-天池数据下载
方法:1.wget ‘网址’网址在这里找,动作讲究一个快准狠,慢了链接就失效了
机器学习-SVM-SMO与SGD求解(附鸢尾花数据集实战,含代码)
代码SMO部分参考书籍为《机器学习实践》首先,我们认识到SVM其实就是求一个最优(超)平面的过程,说svm有三宝,间隔,对偶,核技巧间隔就是说要求得的平面距离所有点间隔最大,这是一个最优化问题,可以用拉格朗日乘数法,解决。化为这个形式后,求它的对偶问题,求解的对偶问题的答案,按照以下公式反推到原问题的答案两种常用的求解算法:1.SGD将原问题转变为一个最小损失函数的问题,用梯度下降的方法,优化参数
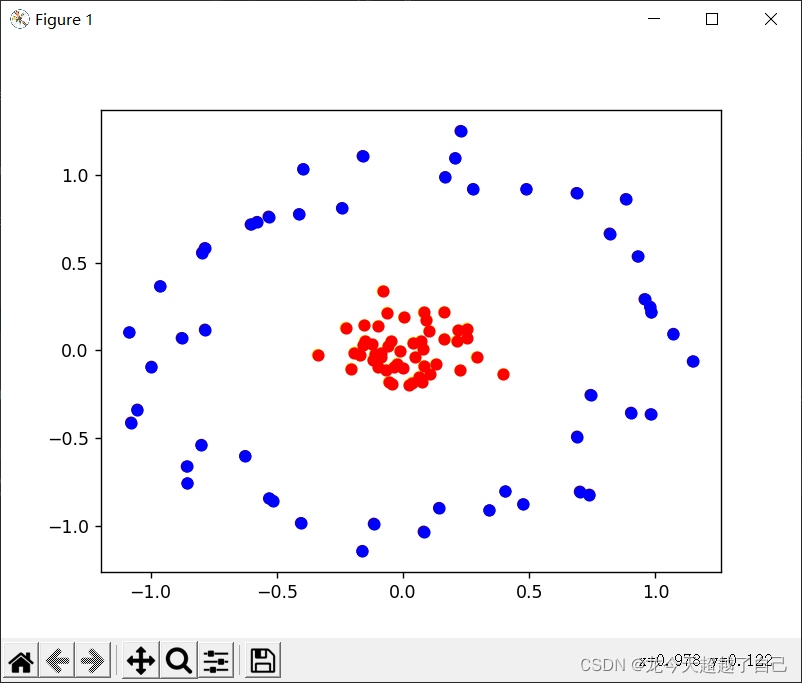
机器学习-决策树算法ID3实现,含例子(红酒分类)
import mathx=[[0,1,"no"],[0,1,"no"],[1,0,"no"],[1,1,"yes"],[1,1,"no"],[1,1,"no"],[1,1,"maybe"],[1,1,"maybe"],[1,1,"maybe"]]# x=[[0,1,"no"],[0,1,"no"],[1,0,"no"],[1,1,"yes"],[1,1,"yes"],]def majorityCn

错误处理-mmdetection-AttributeError: ‘ConfigDict‘ object has no attribute ‘log_level‘
第一次用商汤的mmdetection,遇到很多错误mmdetection中网络的配置文件缺东西,至少缺了log_level参数的值

到底了