- @weixin_47658790
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
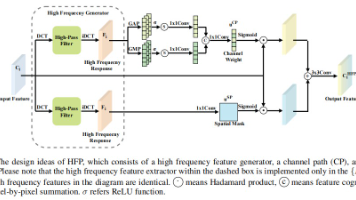
本文提出HS-FPN网络,通过频域和空间感知增强小目标检测。针对小目标特征微弱问题,设计了高频感知模块(HFP)利用DCT变换提取高频特征,增强小目标信号;同时提出空间依赖感知模块(SDP),通过像素级交叉注意力解决特征不对齐问题。实验表明,在AI-TOD数据集上HS-FPN使Faster R-CNN的AP提升2.0,Cascade R-CNN提升3.4。该网络计算开销小,模块可即插即用,适用于小
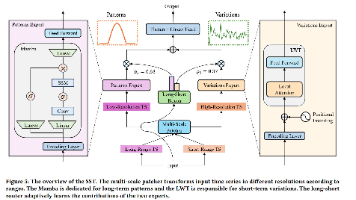
本文提出SST(State Space Transformer)模型,一种创新的多尺度混合专家架构,用于高效时间序列预测。SST通过多尺度补丁机制将序列分解为长程模式和短程变异:Mamba专家处理低分辨率的长程模式(线性复杂度),Transformer专家(LWT)处理高分辨率的短程变异。为解决传统混合架构的"信息干扰"问题,SST采用双分支独立处理,并通过长短路由模块动态融合
本文提出了一种轻量级2.5D跨切片注意力模块CSAM,用于解决各向异性医学图像分割问题。针对MRI等层间分辨率低的特性,CSAM通过解耦语义、位置和切片三个维度的注意力机制,以极少的参数量实现跨切片特征融合。实验表明,该方法在多个医学数据集上优于传统2D、3D方法,显著提升分割精度,特别是改善了层间边界连续性。该模块可灵活集成到现有网络,为各向异性医学图像分析提供了高效解决方案。
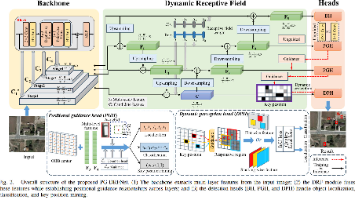
本文提出了一种位置引导的动态感受野网络(PG-DRFNet),用于解决光学和SAR遥感图像中小目标检测的难题。该方法通过位置引导模块(PGM)将浅层网络中的小目标位置信息传递至深层,防止特征淹没;并采用动态感知卷积(DPC)自适应调整感受野形状,精准提取多尺度目标特征。配合组合检测头的辅助监督机制,该网络在多个数据集上达到SOTA性能。核心模块具有即插即用特性,可广泛应用于小目标检测任务。代码已开
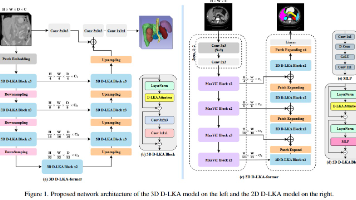
本文提出了一种新型可变形大核注意力机制(D-LKA),通过结合大核卷积的全局感受野和可变形卷积的形状自适应能力,有效解决了医学图像分割中的关键挑战。D-LKA模块通过分解大核卷积模拟自注意力的全局上下文捕捉能力,同时避免了其平方计算复杂度。基于此,作者构建了2D和3D版本的D-LKA Net架构,其中3D版本特别针对伪3D方法导致的层间信息丢失问题,实现了真正的3D上下文感知。实验表明,该方法在多
本文提出HS-FPN网络,通过频域和空间感知增强小目标检测。针对小目标特征微弱问题,设计了高频感知模块(HFP)利用DCT变换提取高频特征,增强小目标信号;同时提出空间依赖感知模块(SDP),通过像素级交叉注意力解决特征不对齐问题。实验表明,在AI-TOD数据集上HS-FPN使Faster R-CNN的AP提升2.0,Cascade R-CNN提升3.4。该网络计算开销小,模块可即插即用,适用于小
本文提出LAM-YOLO模型,针对无人机航拍图像中目标尺寸小、遮挡严重和光照复杂等问题,在YOLOv8基础上引入光照-遮挡注意力机制(LAM)和内卷模块。LAM通过混合注意力增强特征提取能力,改进的检测头和SIB-IoU损失函数提升小目标检测精度。实验表明,该模型在VisDrone2019数据集上mAP提升7.1%,有效解决了复杂场景下的目标检测难题。核心创新包括LAM模块、辅助检测头和SIB-I
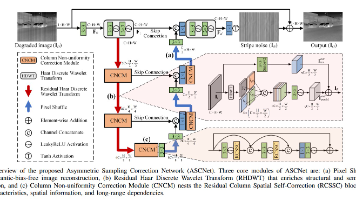
摘要 本文提出ASCNet(非对称采样校正网络)用于红外图像去条纹。针对传统基于小波的U-Net存在的跨层级列语义鸿沟问题,ASCNet创新性地采用残差哈尔离散小波变换(RHDWT)作为下采样器,融合条纹方向先验和数据驱动特征;同时使用像素重组(PS)作为上采样器,避免语义偏差。网络还包含列非均匀性校正模块(CNCM),通过列注意力、空间注意力和自校准分支捕获全局列相关性。实验表明,ASCNet在
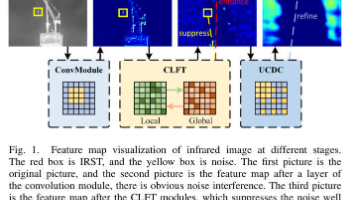
本文提出ABC模型,用于红外小目标检测,通过融合CNN的局部特征提取能力和Transformer的全局相关性建模。核心创新包括:1) CLFT模块,采用双线性注意力计算全局相关性并与局部特征相乘,有效抑制噪声;2) UCDC模块,通过动态调整感受野精细化处理深层特征。实验表明,该方法在抑制虚警和增强目标特征方面具有显著优势,为红外小目标检测提供了新思路。
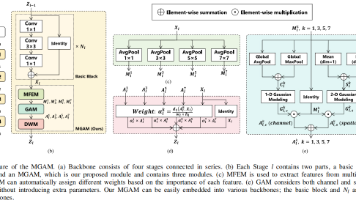
本文提出了一种多尺度高斯注意力机制(MGAM),用于提升遥感图像中微小目标的检测性能。MGAM通过多尺度特征提取模块捕获不同尺度的上下文信息,并采用动态特征加权自适应融合这些信息。其核心创新是引入高斯注意力模块,模拟人类视觉的中心聚焦特性,在不增加额外参数的情况下有效增强模型对微小目标的定位能力。实验表明,MGAM在多个遥感数据集上显著提升了小目标检测精度,尤其在密集场景下表现出色。该模块可即插即