- @weixin_47195452
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
南方医科大学Echo博士将于2026年4月27日直播分享其发表在《Frontiers in Immunology》(IF=5.9)的研究成果。该研究通过整合生物信息学与机器学习,首次揭示泛凋亡(PANoptosis)是驱动糖尿病肾病免疫激活和肾小管间质损伤的核心机制。研究鉴定出6个关键泛凋亡枢纽基因(YWHAH、PRKACB等),构建了具有诊断价值的风险评分模型,并筛选出CASP1、FAS等4个潜
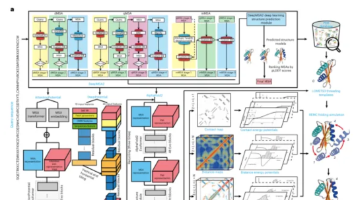
《Nature Biotechnology》最新研究提出混合蛋白质结构预测方法D-I-TASSER,结合深度学习与物理模拟,显著提升预测精度。该方法在单/多结构域蛋白质预测中均优于AlphaFold系列,CASP15盲测表现突出,尤其对复杂多结构域蛋白提升显著。成功预测81%人类蛋白质结构域,与AlphaFold2结果高度互补。研究证明深度学习与物理模拟融合的策略可突破现有技术瓶颈,为结构生物学难
《STAID:一种基于生物信息建模的空间细胞类型去卷积自优化深度学习框架》发表于《Advanced Science》(IF=14.1)。该研究针对空间转录组数据分辨率不足的问题,提出创新性深度学习框架STAID,通过整合伪点生成与模型训练形成自我优化闭环,并引入图信号处理建模基因共表达关系。在乳腺癌、胚胎发育等复杂组织分析中,STAID展现出优于11种现有方法的性能,能精准识别肿瘤细胞群、解析胚胎

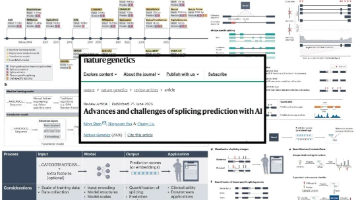
浙江大学良渚实验室沈宁课题组在《Nature Genetics》发表综述,系统回顾了AI驱动的RNA剪接预测算法发展历程,从早期的统计模型到当前的深度学习与基因组大模型。文章重点分析了算法设计中的关键维度,包括训练数据规模、模型结构、预测输出分辨率等,揭示了可变剪接预测正从局部规则向长序列建模、组织特异性预测进阶的转变趋势。随着模型能力的提升,剪接预测算法在临床变异注释、疾病机制研究和靶向治疗设计
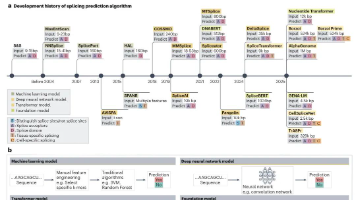
浙江大学沈宁课题组在《Nature Genetics》发表综述,系统回顾了AI驱动的RNA剪接预测算法发展历程。文章指出,从传统统计模型到深度学习和大语言模型,剪接预测精度显著提升,但仍面临组织特异性、突变效应预测等挑战。研究强调,剪接预测需与实验验证结合,在疾病诊断和靶向治疗(如ASO药物设计)中具有重要价值。未来方向应注重多模态数据整合与模型可解释性,而非单纯扩大模型规模。该综述为计算生物学和
斯坦福大学等机构开发的通用生物医学AI智能体Biomni,通过整合150个专业工具、105个软件包和59个数据库(Biomni-E1环境),结合动态任务规划与代码执行能力(Biomni-A1架构),显著提升研究效率。在标准化测试中,其准确率(57%)超越专业AI与人类专家,且耗时大幅缩短(如罕见病诊断从110分钟降至3分钟)。实际应用中,Biomni可自主完成复杂任务,如分析14亿条可穿戴设备数据
本文系统阐述了在生物信息学分析中使用服务器的十大优势,包括接入AI Agent、高配置性能、高性价比、24小时不间断运行、高速网络、专业技术支持、可靠数据存储、原生Linux环境、开箱即用的分析环境和丰富的增值服务。文章还介绍了服务器产品信息,并提供了详细的免费服务器领取流程,帮助生信研究人员高效、稳定地完成数据分析工作。
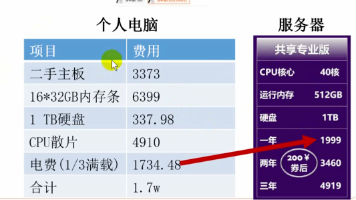
本文系统阐述了在生物信息学分析中使用服务器的十大优势,包括接入AI Agent、高配置性能、高性价比、24小时不间断运行、高速网络、专业技术支持、可靠数据存储、原生Linux环境、开箱即用的分析环境和丰富的增值服务。文章还介绍了服务器产品信息,并提供了详细的免费服务器领取流程,帮助生信研究人员高效、稳定地完成数据分析工作。
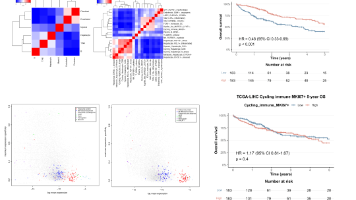
Bulk转录组与单细胞RNA测序联合分析教程 本教程提供了一套整合Bulk RNA-seq与scRNA-seq数据的分析方法,重点结合TCGA临床数据与单细胞分辨率进行生存分析。主要内容包括: 数据准备:TCGA-LIHC数据集处理与单细胞Seurat对象整合 Bulk数据分析:单基因/多基因/临床变量的生存分析(KM和Cox回归) 联合分析方法: 使用BayesPrism进行反卷积,预测Bulk
AI驱动发现跨癌种CAR-T疗法新靶点GPNMB 《Cell》最新研究利用AI技术突破CAR-T疗法瓶颈,通过整合单细胞测序数据与多模态生物信息库,结合ChatGPT-4o等大语言模型系统性筛选,鉴定出糖蛋白GPNMB作为跨血液瘤和实体瘤(如黑色素瘤、结直肠癌)的通用靶点。实验验证显示,GPNMB CAR-T在白血病和多种实体瘤模型中均实现强效杀伤且安全性良好。该研究创新性地建立了AI辅助靶点发现