




- @weixin_46713508
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
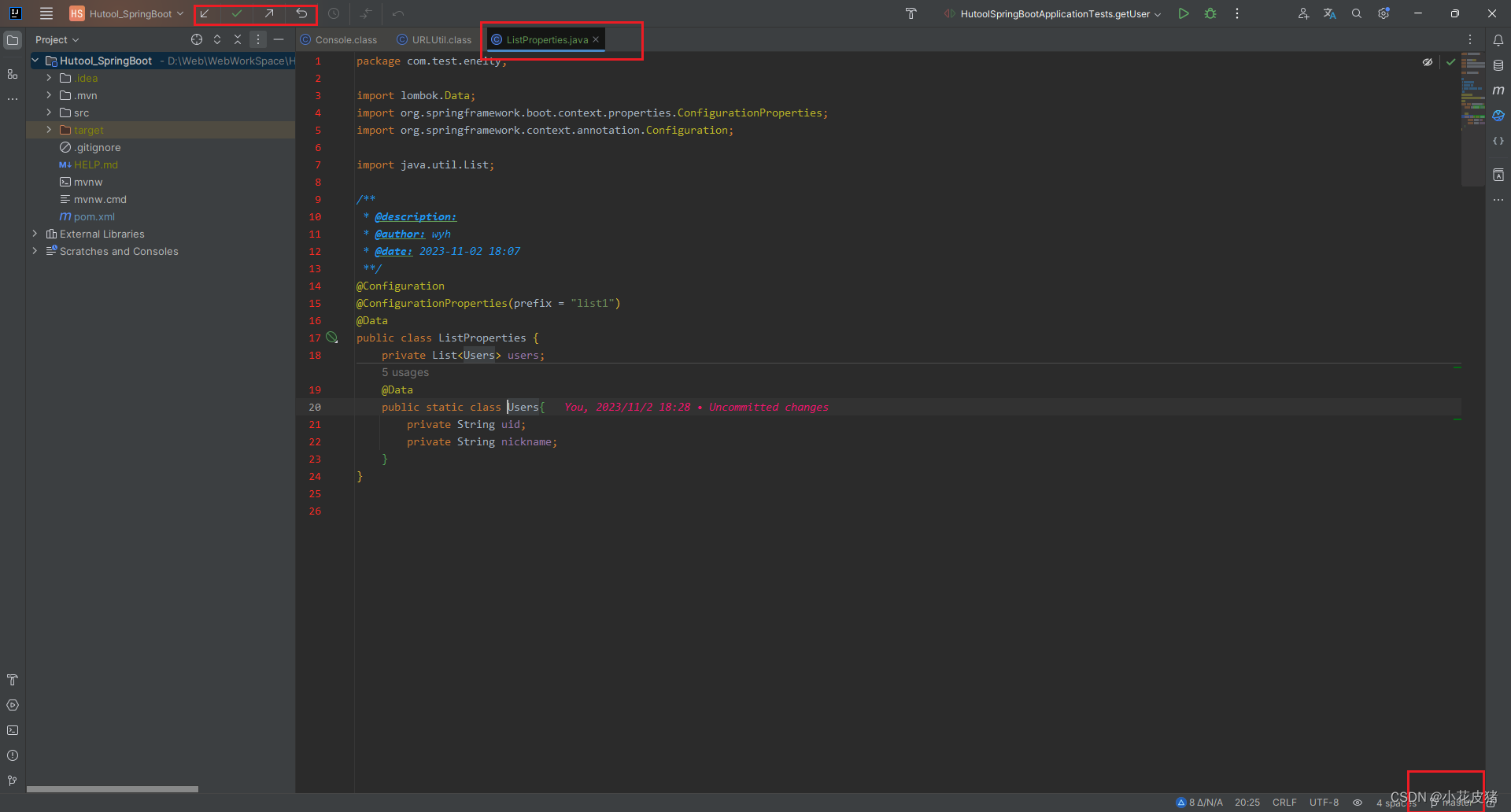
target文件可能时编译的文件被其他程序占用,导致资源无法回收。在cup这里,关联的把柄,输入target。点击性能,点击打开资源监视器。把搜索出来的进程全部杀死。

1:右键项目2:3:
git clone 遇到问题:fatal: unable to access ‘https://github.comxxxxxxxxxxx’: Failed to connect to xxxxxxxxxxxxx将命令行里的http改为git重新执行。
IDEA取消git对项目的版本控制
作为一名AI/ML工程师,之前为为了采集高质量的SERP数据用于LLM训练,我踩过无数坑。最惨的一次,我花了3天写的SERP爬虫,刚跑了1小时就被Google封了IP,之前采集的几百条数据全部作废;后来我又尝试轮换代理、模拟真人行为,可Google的反爬算法更新太快,爬虫维护成本比采集数据本身还高。直到我发现可以直接对接Dify工作流,不用再手动维护爬虫、处理反爬,这才彻底解决了SERP + LL

前言在数据驱动的2026年,网络爬虫早已从程序员的“黑科技”变成了企业标配的数据基础设施。无论是训练AI模型、监控竞品价格,还是做市场舆情分析,都离不开稳健的爬虫。但当我们打开搜索引擎,面对Scrapy、Selenium、Bright Data、Octoparse等琳琅满目的工具时,很容易陷入**“选择困难症”**,本文我将深度评测10款2026年最具代表性的网络爬虫工具。从开源利器到企业级战舰,
Mybatis xml文件中&出现报错问题:Unescaped & or nonterminated character/entity reference如下所示IDEA将“&”当成了特殊符号,一些转义字符在特殊情况下需要转义推荐这种 只需要简单的转义解决方式2需要修改连接数据库配置信息,不太推荐......
IDEA配置mapper.xml模板<?xml version="1.0" encoding="utf-8" ?>
前言今天遇到一个问题,做一个接口返回oracle数据库表中的数据,但是某个字段含有html标签,显示的时候会把这些标签显示出来影响效果,就想到用oracle正则把这些标签去除掉sql语句如下--正则验证去除html元素select regexp_replace(要去除的字段,'</?[^>]*>|nbsp;|&','')from 你的表名注意:这个sql有些问题,有的元素
Cause: java.lang.UnsupportedOperationException] with root cause java.lang.UnsupportedOperationException: nullmapper层接口List selectRolePredict(@Param("organId") String organId,@Param("businessId") Strin