




- @weixin_46264660
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
维度为 1 的位置有元素吗?有,且只有一个。移除会丢失信息吗?不会。数值、精度、顺序完全不变。什么时候移除?当你需要把数据送入那些“嫌弃”多余维度的层(比如全连接层 Linear),或者你想简化索引时。什么时候保留?当你需要进行张量之间的算术运算(加减乘除),且需要维度对齐时。你可以把 squeeze 想象成脱掉外壳。壳子没了,但核心的内容物始终都在。在深度学习中,张量总元素个数是不变的,改变的只
传统的池化层需要你告诉它:“我想用的窗口来扫描”。而自适应池化则是你告诉它:“无论输入多大,我最终只要的输出它会自动计算内部的和stride,从而保证输出尺寸的固定。这在处理全连接层(FC)之前的特征对齐时至关重要。特性传统 AvgPool2d参数焦点窗口大小、步长输出目标尺寸灵活性输入改变,输出随之改变输入改变,输出始终固定典型场景固定感受野的下采样特征融合、注意力机制、FC层输入对齐💡 结语
本文介绍了YOLO模型验证与数据集转换的完整流程。首先说明验证时需要开启save_json选项以保存结果,并提供了验证代码示例。其次详细讲解了将YOLO格式数据集转换为COCO格式的方法,包括类别定义、坐标转换和JSON文件生成。最后介绍了使用TIDE工具获取评估指标的步骤,包括安装依赖和运行评估脚本。整个过程涉及图像路径处理、标签文件转换和COCO格式数据生成,为模型验证和评估提供了完整的技术方
Pytorch的GPU版本查看GPU是否可用、GPU版本、GPU数量
无人机目标检测(UAVOD)面临着高度变化、动态背景以及目标尺寸小等独特挑战。传统检测方法往往难以应对这些问题,因为它们通常仅依赖视觉特征,无法提取目标之间的语义关系。为解决这些局限性,我们提出了一种名为自提示类比推理(SPAR)的新方法。该方法利用视觉语言模型(CLIP)基于图像特征生成上下文感知提示,提供丰富的语义信息以指导类比推理。SPAR 包含两个主要模块:自提示模块和类比推理模块。自提示
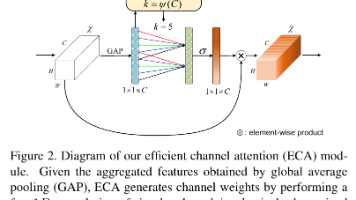
摘要:ECA-Net是一种轻量级通道注意力机制,旨在以极低计算开销提升卷积网络性能。其核心创新包括:1) 移除降维操作保留通道信息完整性;2) 使用自适应一维卷积核捕捉局部通道依赖;3) 通过全局平均池化、一维卷积和Sigmoid激活实现高效计算(复杂度O(C×k));4) 模块化设计可即插即用。相比SENet,ECA-Net避免了信息损耗,参数更少,能灵活适配不同网络层,在分类、检测等任务中表现
Pytorch的GPU版本查看GPU是否可用、GPU版本、GPU数量
在机器学习中,尤其是深度学习领域,YOLO(You Only Look Once)算法的训练过程依赖于训练集、验证集和测试集的合理划分与使用。训练集用于模型的学习和参数调整,验证集用于模型选择和超参数优化,而测试集则用于最终评估模型的泛化能力。
本文介绍了YOLO模型验证与数据集转换的完整流程。首先说明验证时需要开启save_json选项以保存结果,并提供了验证代码示例。其次详细讲解了将YOLO格式数据集转换为COCO格式的方法,包括类别定义、坐标转换和JSON文件生成。最后介绍了使用TIDE工具获取评估指标的步骤,包括安装依赖和运行评估脚本。整个过程涉及图像路径处理、标签文件转换和COCO格式数据生成,为模型验证和评估提供了完整的技术方
是的,深层特征是“被下采样很多次的小图”:这指的是它的空间尺寸。它牺牲了精细的空间细节(精确坐标)。同时,它包含“全局的高级信息”:这是因为它的每个像素都拥有巨大的感受野,并且其数值代表的是经过高度抽象和提炼的语义概念(是什么物体、什么场景)。简单来说:网络用“空间精度”换取了“语义深度”。这种权衡对于需要高级理解的视觉任务(如分类、检测)来说是极其高效和有效的。而对于需要同时恢复细节的任务(如图