- @weixin_45954198
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
报错:运行:原因:‘n_jobs’在0.23版本已弃用,并且将会被弃用解决方法:去掉即可运行:
成功解决:'javac' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
2.将该字体文件 拖到 C:\Windows\Fonts目录下安装即可。1.获取“STXingkai(华文行楷)”字体文件。
2.将该字体文件 拖到 C:\Windows\Fonts目录下安装即可。1.获取“STXingkai(华文行楷)”字体文件。
【Unity报错】Assets(Player.cs(40,34): eror CS0117:'Input' does not contain a definition for'GetkeyDown'

html.parser:html.parser 是Python3中的一个解析器,不需要单独安装。(如果不是特殊场景的需要,大都使用这个解释器)lxml:1.与 html.parserxingmu ,lxml的优点:在于解析"杂乱"或者包含错误语法的HTML代码的性能更优一些。2.(它可以容忍并修正一些问题,例如未闭合的标签、未正确嵌套的标签,以及缺失的头(head)标签或正文(body)标签。)3
Python 分别与 TensorFlow 和 Torch/Torchvision 的版本对应(参考表)
导入categorical时报错,如下解决方法:将:from keras.utils import to_categorical改为:from tensorflow.python.keras.utils.np_utils import to_categorical即可
具体实现:打开Options ——> 点击 Configure TeXstudio ——> Build ——> 找到默认编辑器,选择XeLaTex ——>点击 OK 即可。将默认的编译器切换成XeLaTeX,

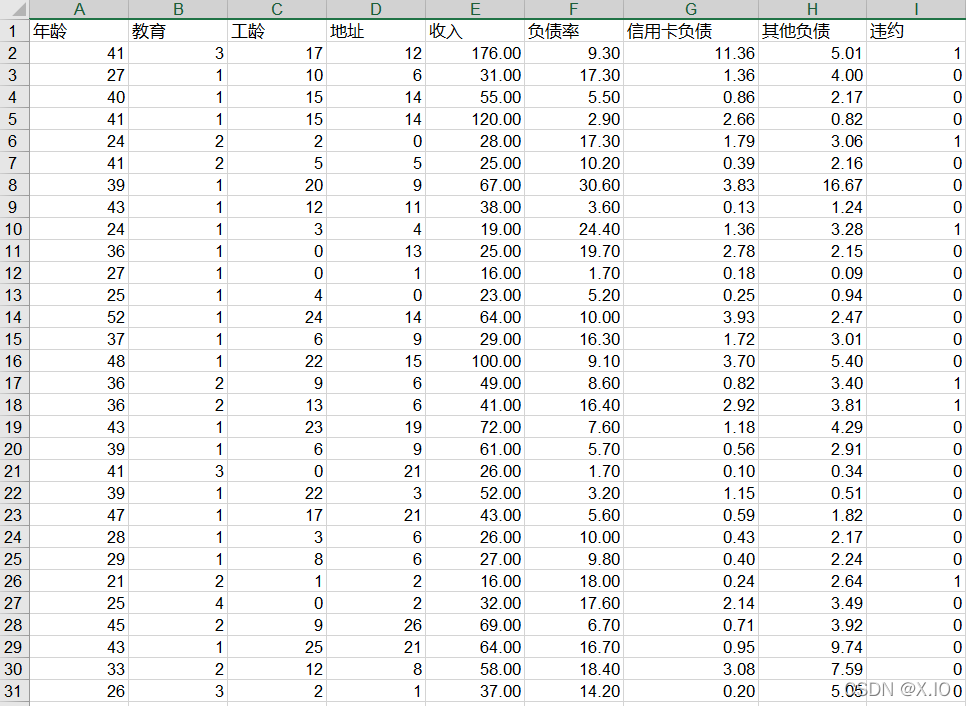
数据:(部分数据展示:)图:银行贷款拖欠率数据代码清单:import pandas as pdfrom sklearn.linear_model import LogisticRegression as LR#参数初始化filename = '../data5/bankloan.xls'data = pd.read_excel(filename)x = data.iloc[:,:8].values