




- @weixin_45880765
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
4.ollama拉取deepseek:7b模型并运行。1.创建并配置docker-compose.yml。5.ollama拉取qwen2.5:7b模型并运行。6.docker查询容器日志。2.拉取镜像并启动服务。
1)方法1:通过将hdfs的两个配置文件(hdfs-site.xml、core-site.xml)放到resources文件夹下后,新建Configuration的时候设置为true会自动读取,也可以通过conf.set(“配置”,“值”)来修改配置项。11)递归查询目录所有文件信息,比listStatus多了文本大小,副本系数,块大小信息。3)创建文件夹并设置权限为文件所有者可读可写,文件所有组

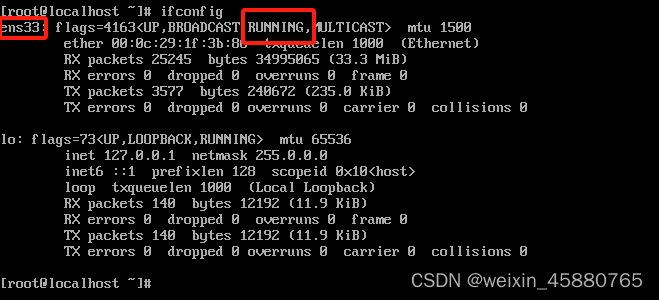
1)使用ifconfig查询<>里是否有RUNNING,表示网线是否连接上,存在NO-CARRIER的话代表该网卡无网线连接。2)也可以使用ip addr看,存在NO-CARRIER的话代表该网卡无网线连接。ens***是上面步骤查到的网卡,这里是ens33。正常情况下,进行简单配置即可。
4.ollama拉取deepseek:7b模型并运行。1.创建并配置docker-compose.yml。5.ollama拉取qwen2.5:7b模型并运行。6.docker查询容器日志。2.拉取镜像并启动服务。
4.ollama拉取deepseek:7b模型并运行。1.创建并配置docker-compose.yml。5.ollama拉取qwen2.5:7b模型并运行。6.docker查询容器日志。2.拉取镜像并启动服务。
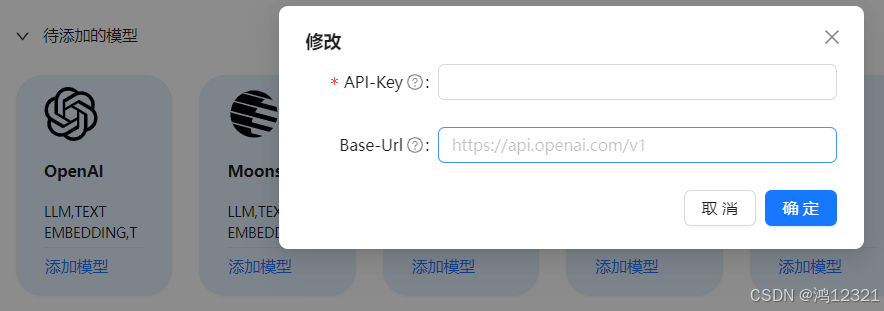
接入时会把openai的默认模型都接入进去,如果openai的令牌只有deepseek或其他模型,会出现该令牌无权使用模型的提示。ragflow在接入OpenAi时,只能选择输入api-key和base-url。
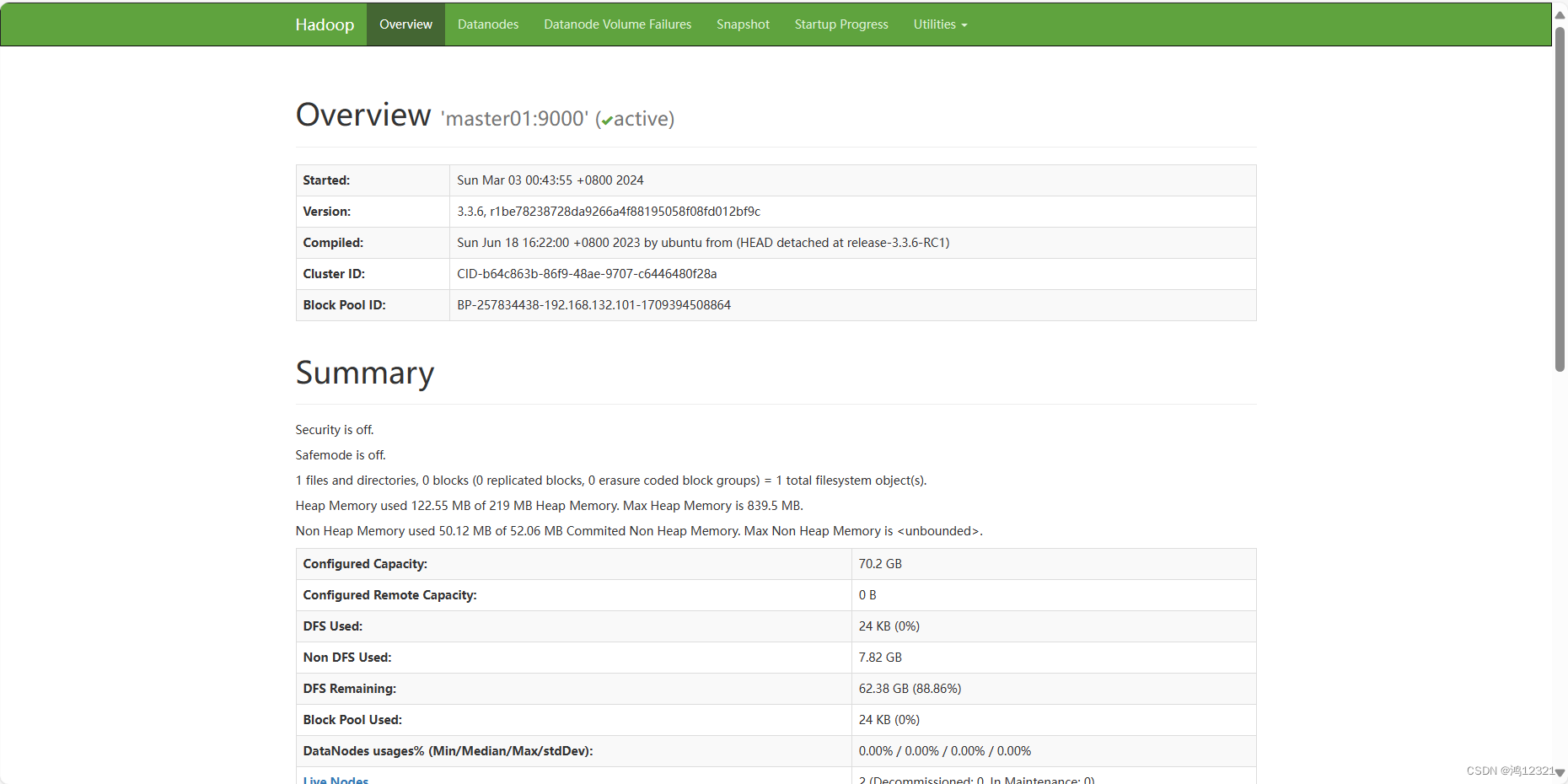
日志保存的信息比较完全但恢复启动慢,镜像的恢复启动比较快但更新速度有限,所以要周期性地将日志的信息更新到镜像中,然后删除日志,最后使用镜像+日志进行NameNode的启动。:需要3台服务器节点,一台NameNode节点,两台DataNode节点,另外还需要一个SecondaryNameNode,可放在DataNode节点里。三个节点分别命名分别为master01,node01,node02,并配置
4.ollama拉取deepseek:7b模型并运行。1.创建并配置docker-compose.yml。5.ollama拉取qwen2.5:7b模型并运行。6.docker查询容器日志。2.拉取镜像并启动服务。
4.ollama拉取deepseek:7b模型并运行。1.创建并配置docker-compose.yml。5.ollama拉取qwen2.5:7b模型并运行。6.docker查询容器日志。2.拉取镜像并启动服务。
接入时会把openai的默认模型都接入进去,如果openai的令牌只有deepseek或其他模型,会出现该令牌无权使用模型的提示。ragflow在接入OpenAi时,只能选择输入api-key和base-url。