- @weixin_45304503
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
物以类聚经典的无监督学习算法——K-Means聚类算法目录1. K-Means 定义2. K-Means 步骤1. K-Means 定义K-means聚类算法首先是随机选取K个对象作为初始的聚类中心,然后计算每个样本与各个聚类中心之间的距离,把每个样本分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一次样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不
基于YOLO+ResNet50的手势识别(一)项目背景以及系统环境本文所使用的深度学习框架为pytorch-gpu-1.7.1版本,python3.7版本,需要在特定的系统环境中运行。本文搭建实验所需要的系统环境如下所示。1.1 项目背景近年来,计算机视觉技术蓬勃发展,为生产和生活带来了巨大的变革。像是刷脸支付、无人驾驶等已经上市或即将走向成熟的技术,极大便利了我们的日常生活。但是我们观察到,目

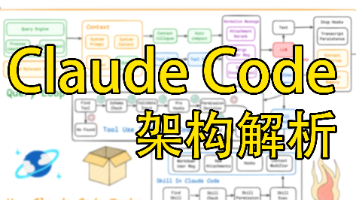
当一个 Agent 单 Loop 干不完一件事的时候,怎么办?放在之前那就是 multi-agent、ReAct + planner、各种 static workflow, LangGraph 之类的解决方案。新答案是——让 Agent 自己写一个一次性的、为这个任务量身定做的 harness。我感觉这是一个很大的范式转变,所以这篇想把它讲清楚。这篇我们来讲讲,也就是 Claude 自己写 har
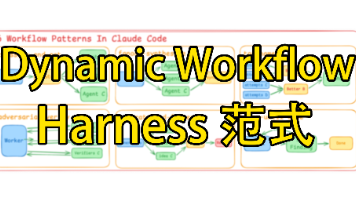
当一个 Agent 单 Loop 干不完一件事的时候,怎么办?放在之前那就是 multi-agent、ReAct + planner、各种 static workflow, LangGraph 之类的解决方案。新答案是——让 Agent 自己写一个一次性的、为这个任务量身定做的 harness。我感觉这是一个很大的范式转变,所以这篇想把它讲清楚。这篇我们来讲讲,也就是 Claude 自己写 har
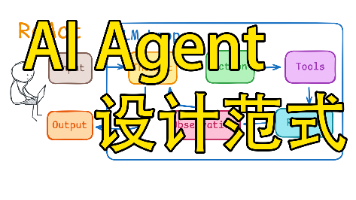
最近接触 agent 开发比较多,这篇文章来讲一下Agent开发中,常用的三种设计范式。。这几种模式主要是工作流程的不同。
如何维护Session对话呢?为了让大模型的输入prompt更精准,我们可以使用Vector DB存储,也就是。
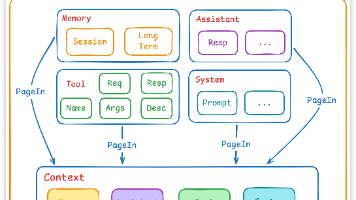
最近一直在做 Agent 工程化的事情,越来越感觉Memory在整个架构中的承受巨大的作用。Tool 和 Skill 可以靠 Prompt 和工程兜底,但是一个 Agent 能不能明白当前的意图,能不能跨 session 持续做事,本质上看的是记忆系统怎么设计。这篇文章我就来聊一下我自己的理解:记忆在 Agent 里到底是怎么存、怎么取、怎么更新的。
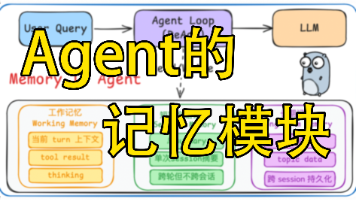
Claude Code和大多数的Agent架构类似,不过里面有非常多的细节可以耐人寻味的,包括 多重压缩的上下文治理,消息的顺序与补充,以及文章这里没提到的多重权限管理等等…从我自己做Agent的角度来看,Prompt 和 记忆选取也是很重要的,调Prompt过程非常痛苦。下篇文章,我们就来讲讲Claude Code里面的Prompt和记忆管理模块。