
【图解】记忆在 Agent 中存储、读取与更新
写在前面
最近一直在做 Agent 工程化的事情,越来越感觉 Memory 在整个架构中的承受巨大的作用。
Tool 和 Skill 可以靠 Prompt 和工程兜底,但是一个 Agent 能不能明白当前的意图,能不能跨 session 持续做事,本质上看的是记忆系统怎么设计。这篇文章我就来聊一下我自己的理解:记忆在 Agent 里到底是怎么存、怎么取、怎么更新的。
⚠️ 注意:这里主要是工程的实践视角,里面结合一些开源框架Claude Code、Mem0、LangMem等等的设计思路,以及我自己做 Agent 时踩过的坑。
记忆模块整体架构
我们先看一下整体架构图:
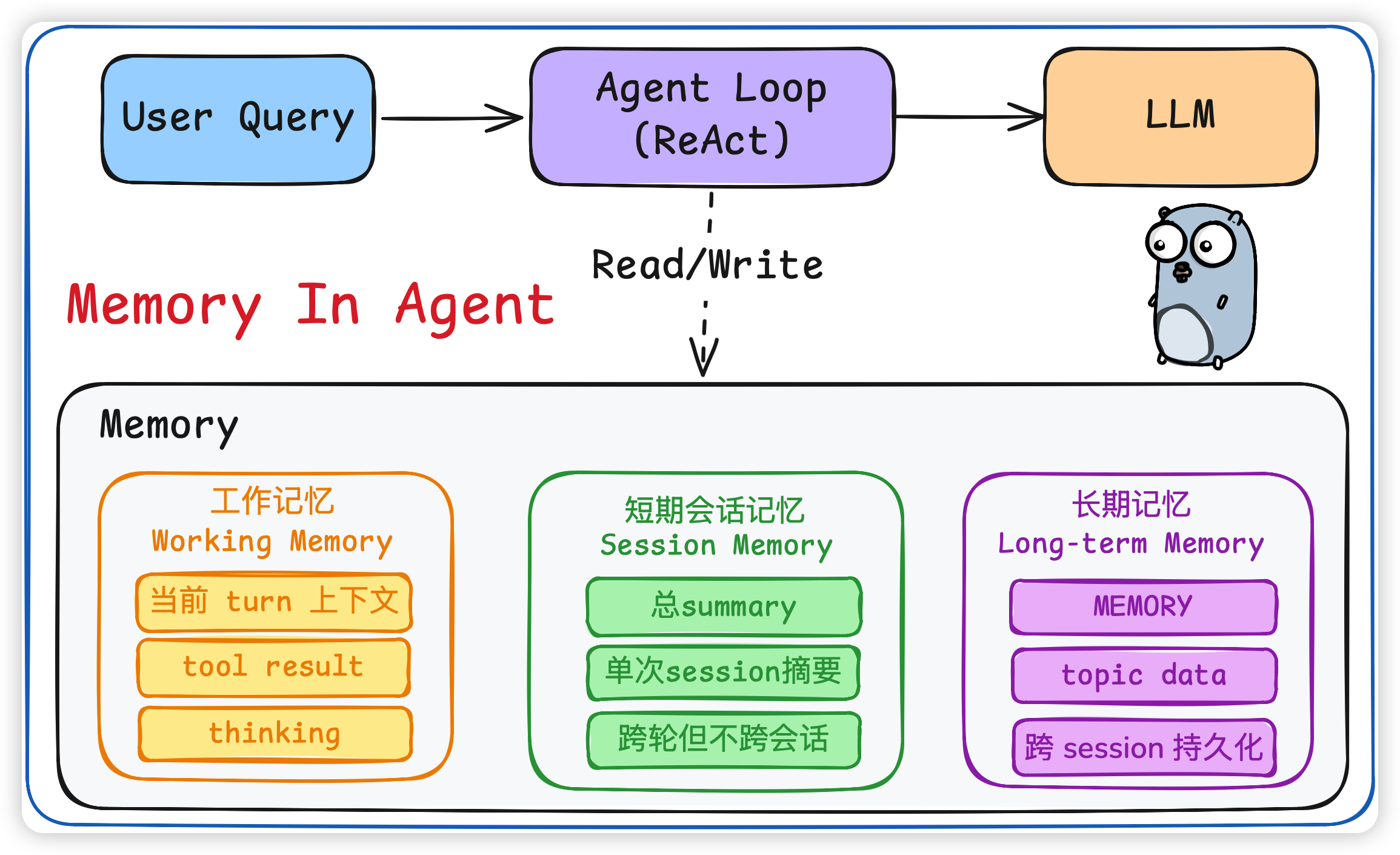
整个 Memory 模块从生命周期上分成三层,这三层是大多数工业级 Agent 的标配:
- 工作记忆 (Working Memory):就是当前这一轮 LLM Loop 的上下文,包含 user message、assistant message、tool_use、tool_result、thinking 等等。它的生命周期就是
一次 LLM 调用。 - 短期会话记忆 (Session Memory):跨轮但不跨会话。比如 CC 里的
summary.md,达到一定 token 阈值或者 tool call 数之后,会 fork 一个受限 SubAgent,把当前 session 重新摘要一遍。 - 长期记忆 (Long-term Memory):跨 session 持久化。CC 里就是
MEMORY.md+ 一堆topic files;Mem0 / LangMem 里就是向量库 + 元数据库。
⚠️ 注意,这三层有 互相喂数据 的这么一层关系:
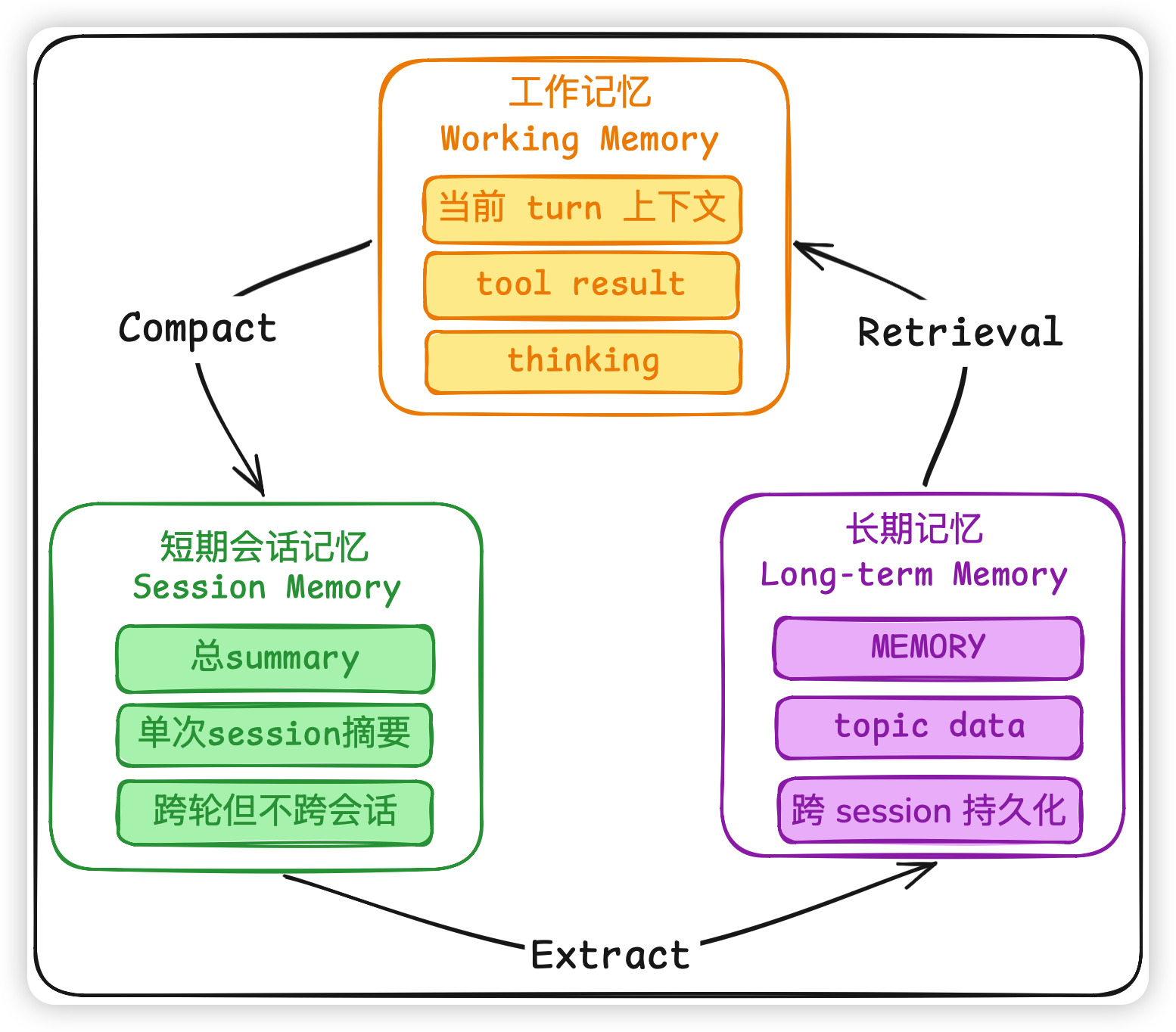
- Working Memory → Session Memory:走压缩、摘要、Autocompact
- Session Memory → Long-term Memory:走 Memory Extraction 做提取到长期记忆
- Long-term Memory → Working Memory:走检索注入(核心动作)
下面我们就分别展开讲三件事:怎么写、怎么读、怎么更新。
Memory 怎么存进去(Write)
记忆模块的难点更多在写,也就是 Memory Extraction:从一堆乱七八糟的对话里,挑出真正值得长期记的东西。我们看一下写入流程:
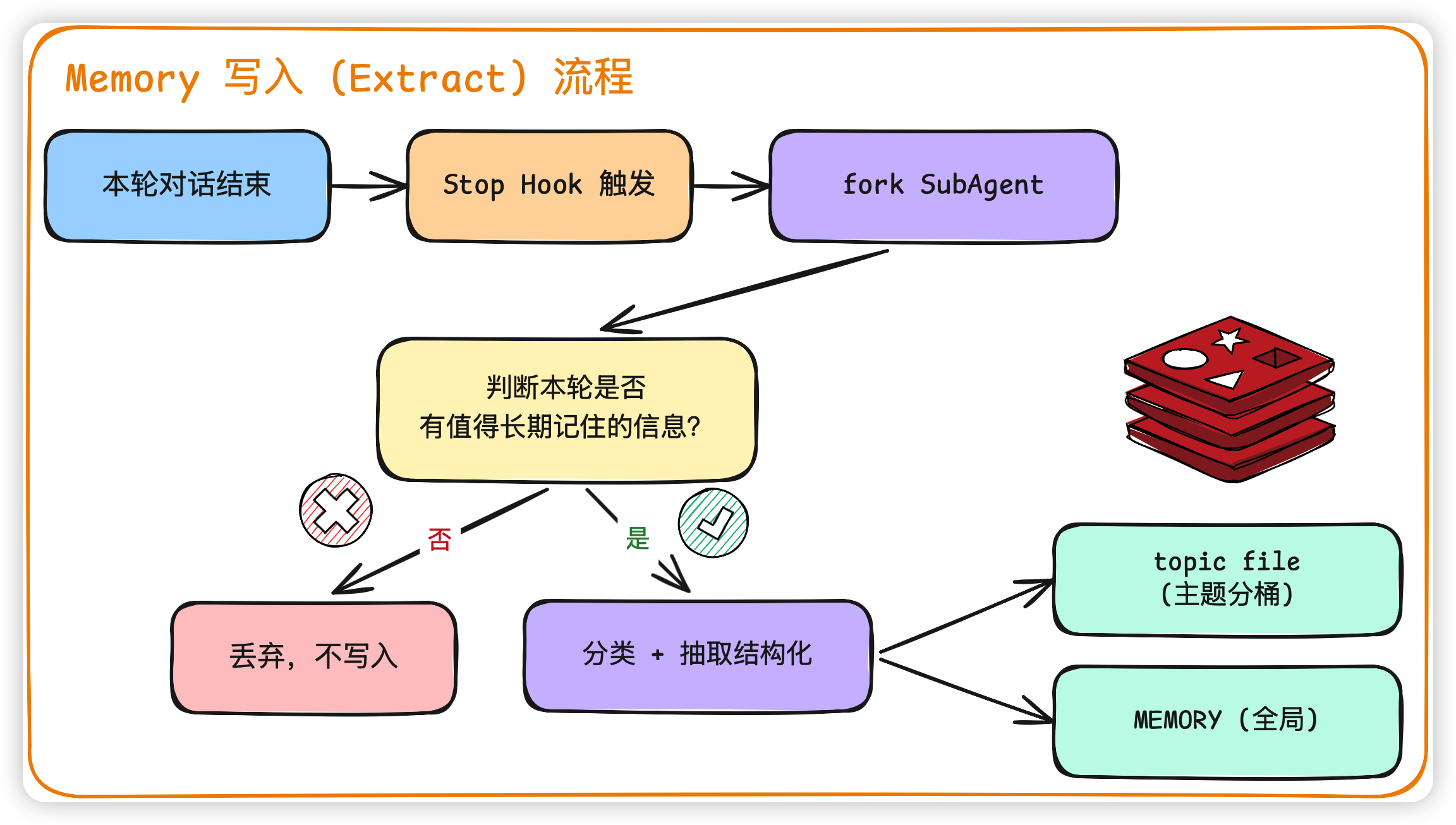
整个写入流程主要做这几件事:
1. 时机:Stop Hook 触发
CC 里面是放在每一轮的 stop hook 里做的,不会在每一次 tool_call 之后就记一笔,因为那样会非常杂乱。在一轮对话 完整结束之后,再 fork 一个独立的 memory extraction subagent 去做这件事。
⚠️ 这里有个很关键的设计:memory subagent 是受限的,它只允许读 / 写 memory 目录,不允许调其他工具。这种权限边界在工业级 Agent 里非常重要,否则一个 extract memory 的小动作可能会把整个 session 搞乱。
2. 判断:值不值得记
不是所有信息都要记,如果记忆一周后还重要,才值得长期记,一般会用轻量的判别 prompt 让 SubAgent 判断:
- 用户偏好 ✅:比如"我喜欢简洁回答"、“我用 Go 写后端”
- 环境事实 ✅:比如"项目用 pytest"、“OS 是 macOS 14”
- 稳定约定 ✅:比如团队的 git 规范
- 任务进度 ❌:比如"PR 已合并"、“今天修了 bug X” —— 这种信息一周后就过期了
- 临时上下文 ❌:比如本次的命令行输出
3. 分类 + 抽取结构化
判断完之后做分类抽取,一般会落到两种文件:
- topic file:按主题分桶。比如
topics/python.md、topics/user_preferences.md - MEMORY.md:全局快照,每次对话开始时整个塞进 system prompt
这里有个 trade-off:topic file 多了检索好但首轮Token多且贵;MEMORY.md 全量注入但容量有限。CC 的做法是 MEMORY.md 主要放最高优先级,长尾内容走 topic file + 检索。
4. 写入方式:陈述句而不是命令
这个细节可能大家注意的不多:记忆的句式应该是陈述事实,不是命令模型。举个例子:
✅ 项目用 pytest 做测试(陈述句)
❌ 用 pytest 跑测试(祈使句)
为什么?因为 memory 在下一次 session 会被作为 system prompt 注入回去,祈使句会被模型当成当前用户的指令重新执行,因为system prompt得优先级要比user prompt的要高,所以可能直接覆盖用户这次的真实诉求。
Memory 怎么读出来(Retrieve)
存的部分是离线的、容错的,但读的部分是 在线的、强延迟敏感的 。每一次 user query 进来,我们都要决定:这次要不要查记忆?查哪些桶?怎么排序?注入多少? 一般的读取流程如下图所示: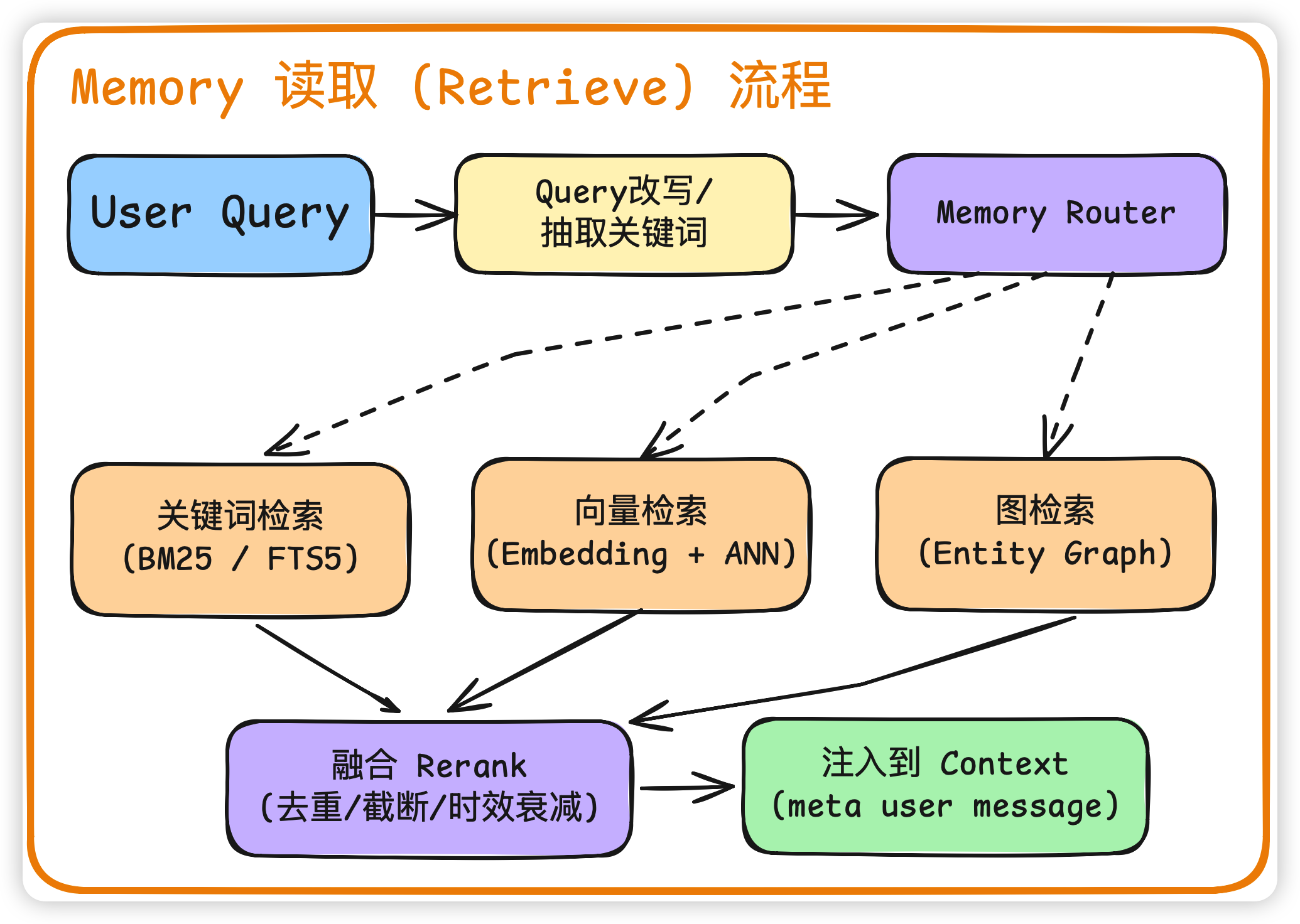
1. Query 改写
直接拿原 query 去检索效果一般不太好,一般会先做一次 query rewrite。比如把代词解析掉(“它” → “上次提到的 todolist 项目”),抽取实体(人名、项目名、技术栈)等等
2. Memory Router:决定查哪条路
我觉得这一环节可能比较容易被忽略。核心原则:不是每一次 query 都需要全套检索:
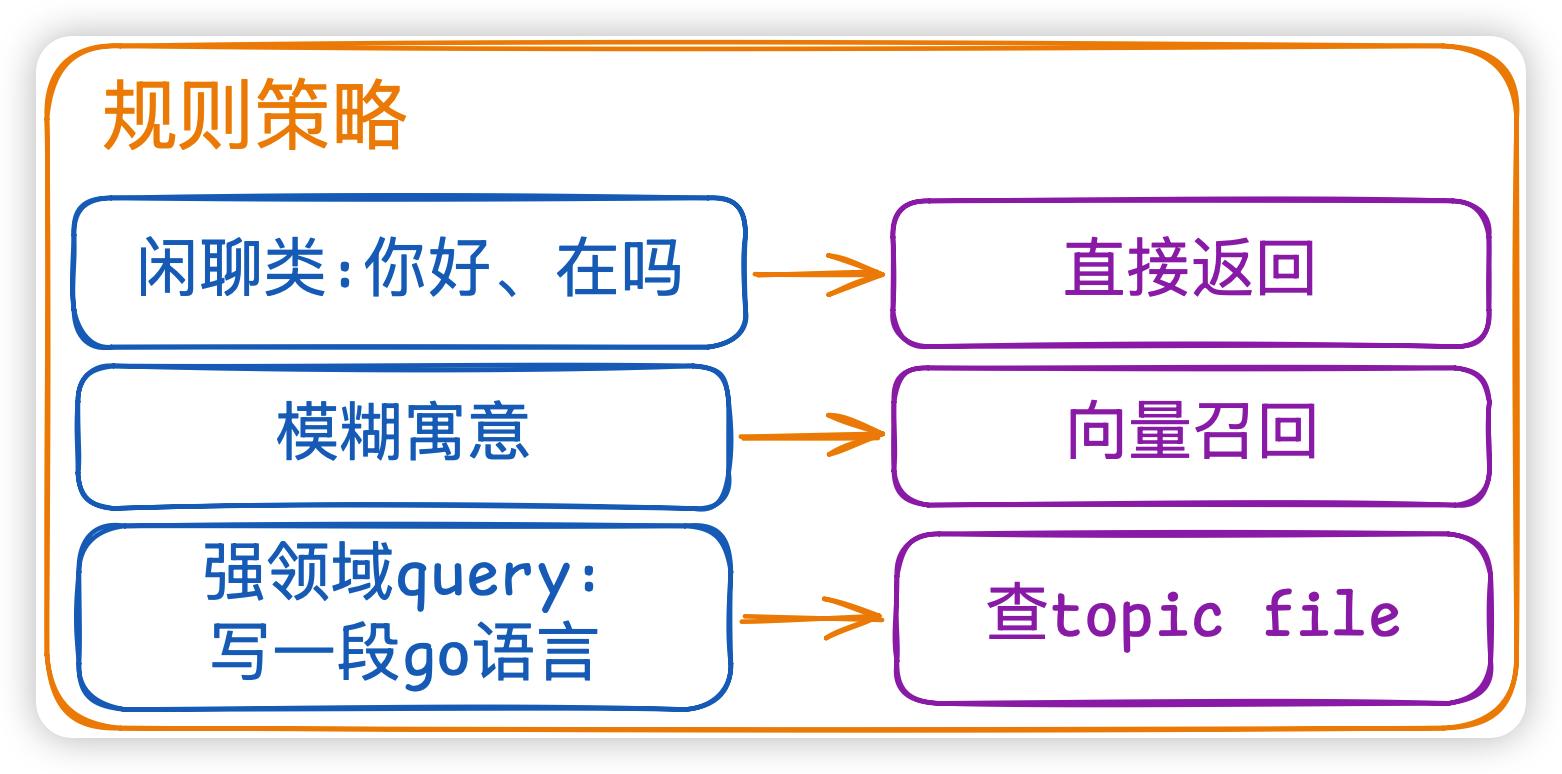
Router 这一层会决定 Agent 的成本和首字延迟。加一个轻量的 router,能砍掉 30% 不必要的 embedding 调用。
3. 多路召回
工业上常见的搭配是 关键词 + 向量 + 图 的三路混合检索:
- 关键词 (BM25 / FTS5):精确实体、专有名词
- 向量 (Embedding + ANN):语义相似
- 图 (Entity Graph):跨记忆关联,比如"用户喜欢 X,X 属于 Y"这种二跳推理
Mem0、LangMem、Zep 这些开源项目卷的就是这一块。
4. 融合 Rerank
三路召回的结果要融合成一个有序列表,常见做法:
- 去重:不同路召回到同一条 memory,合并打分
- 时效衰减:越新的 memory 给越高权重(除非是被显式标记为永久事实)
- trust score 加权:被多次命中且没被用户纠正的 memory,权重更高
- 截断:最终只取 Top-K(一般 3~10 条),避免污染上下文
5. 注入到 Context
CC 这里的做法很值得参考:把检索到的 memory 包成一个 meta user message,放到 messages 数组的最前面,而不是塞到 system prompt 里。这样做有两个好处:
- system prompt 可以做静态缓存,KV cache 不会失效
- meta user message 是动态的,每轮可以变化,符合"记忆是会动的"这个直觉
⚠️ 注意:注入的内容一定要带边界标记,比如 <memory>...</memory>,让模型清楚这部分不是当前用户说的话,而是 Agent 自己回忆出来的。
Memory 怎么更新(Update)
如果只有"加"没有"改"和"删",那记忆系统就会变成一个垃圾场。这一节我们就来聊聊更新策略。
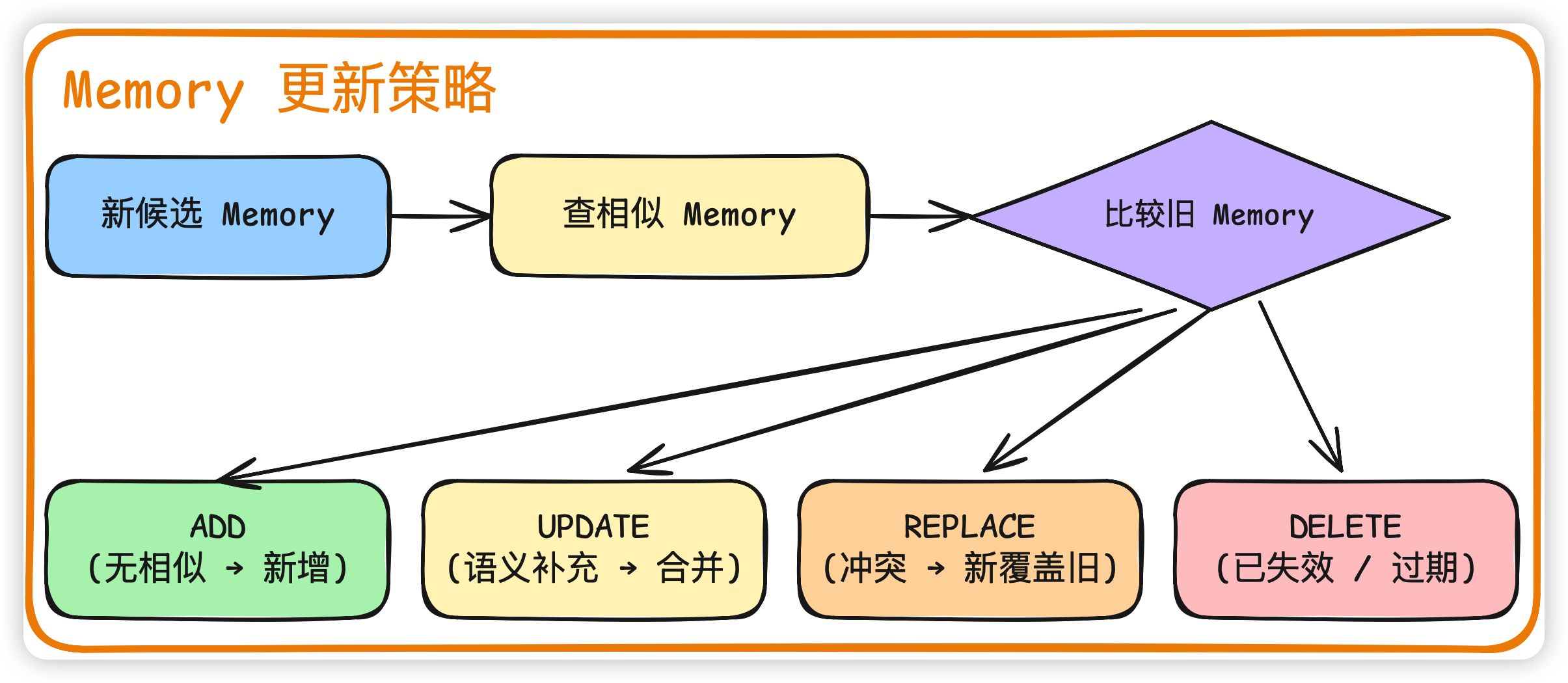
新候选 memory 进来之后,不能直接添加,必须先做一次和已有 memory 的比较,然后决定走四条路中的哪一条:
ADD(无相似 → 新增)
新 memory 在向量空间里没有任何近邻,那就是真的全新事实,直接写入。
UPDATE(语义补充 → 合并)
新旧 memory 在讲同一件事但互相补充: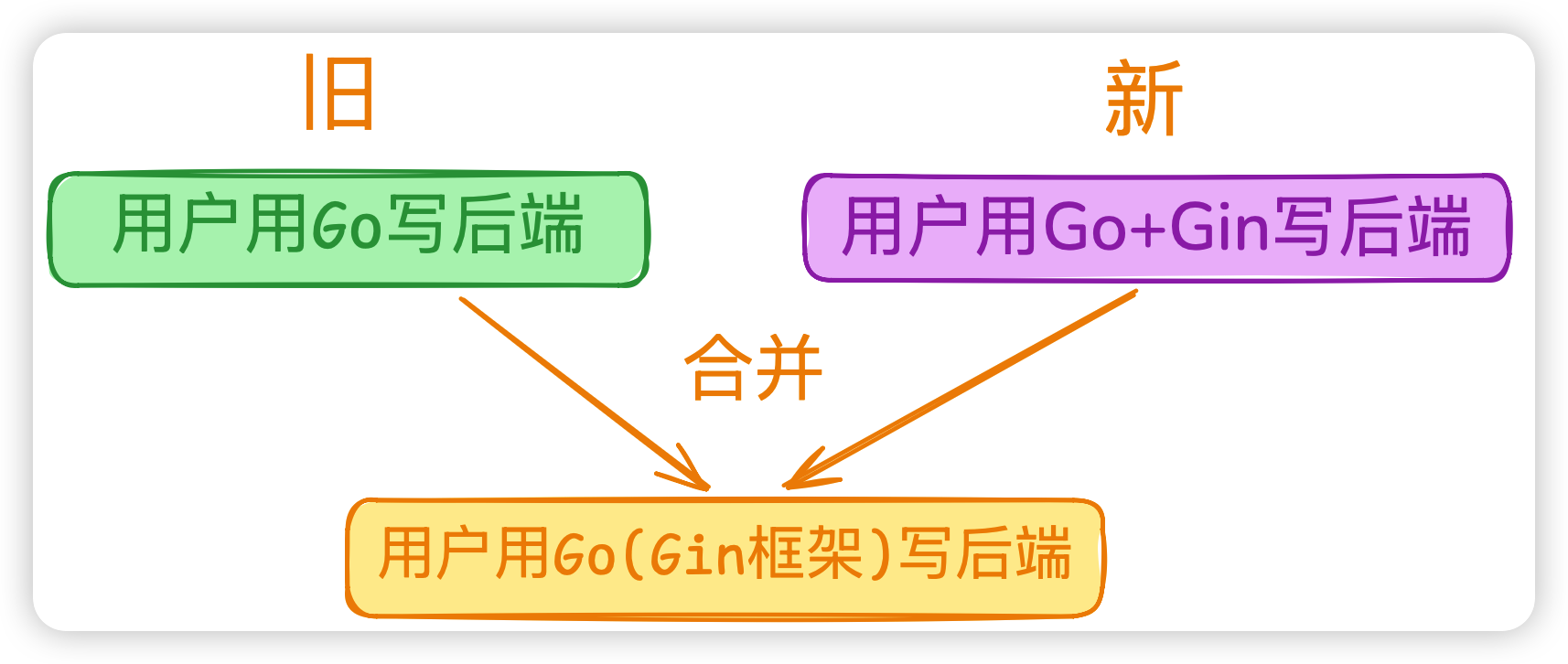
合并比新增重要一点,因为它防止了 记忆膨胀 。
REPLACE(冲突 → 新覆盖旧)
新旧 memory 在讲同一件事但互相矛盾: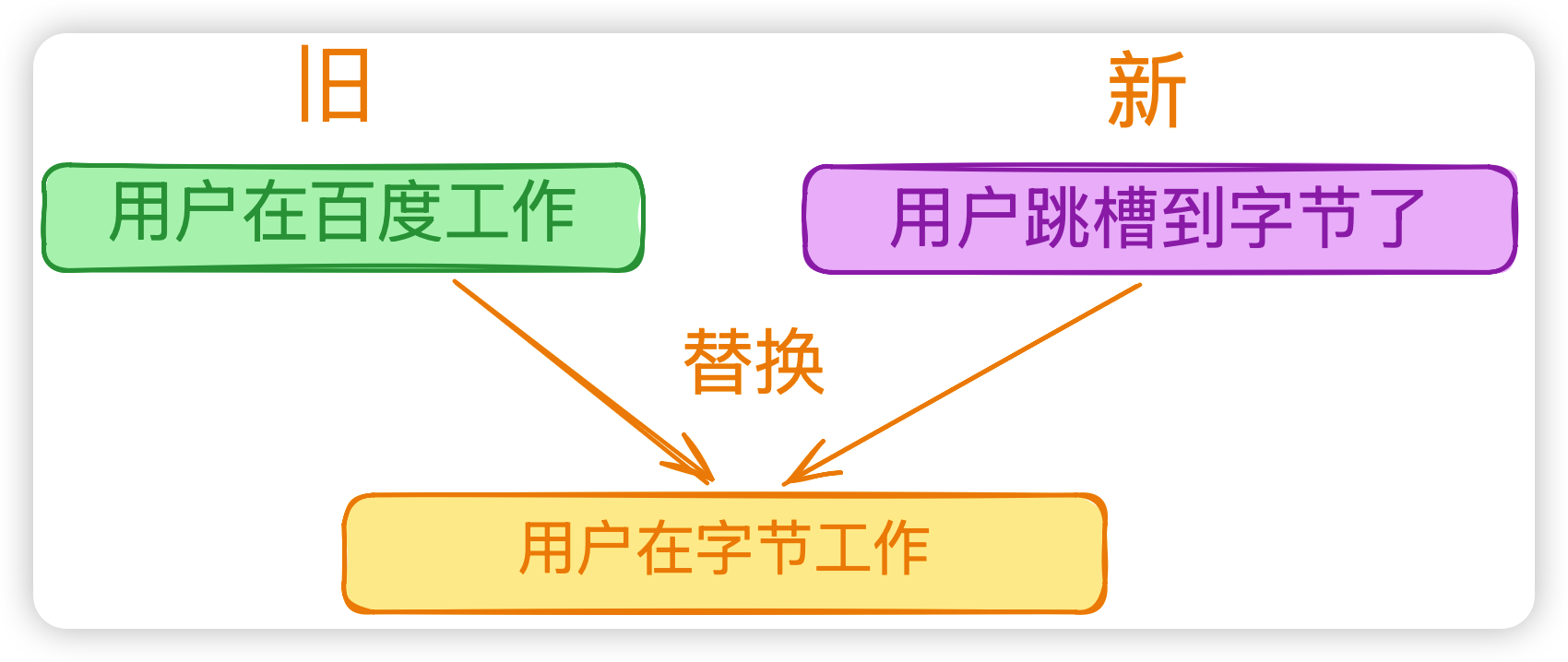
这是更新里最难也最关键的一步。怎么判断"矛盾"?常见做法是用一个小模型做 NLI(自然语言推理):判断 new vs old 的关系是 entailment / contradiction / neutral。
⚠️ 注意:REPLACE 要保留版本历史,不要真的物理删除,而是把旧的标记为 deprecated, 方便追溯和回滚。 避免删干净之后用户某天问"你之前还记得我说过 XX 吗",就尴尬了。
DELETE(已失效 / 过期)
最直接的两种场景:
- 用户显式说"忘掉这件事"
- 时效性记忆过期(比如"本周末出差",下周自动失效)
Trust Score:让记忆"自我净化"
我们可以看看 Hermes 是怎么做的: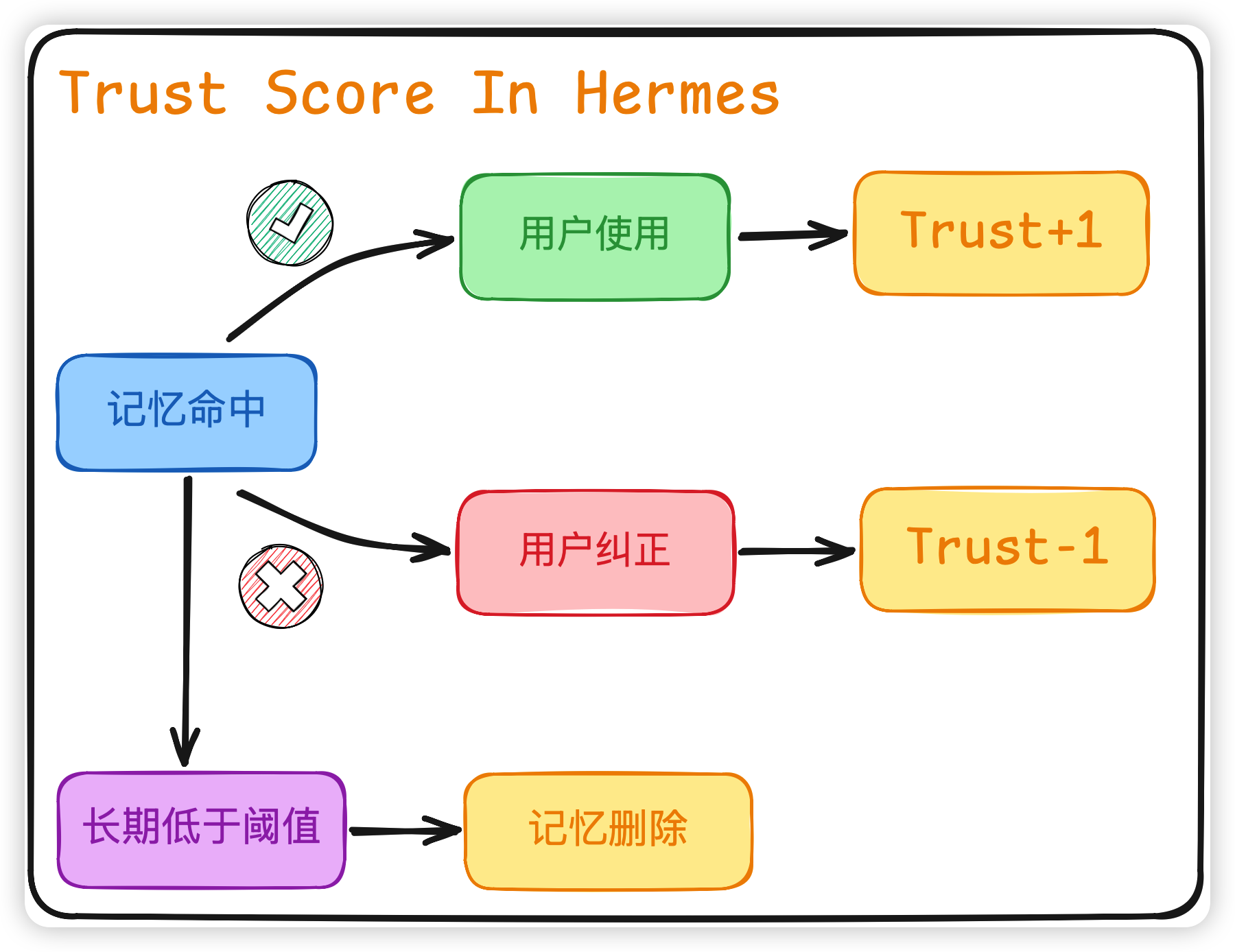
- 每条 memory 带一个
trust ∈ [0, 1] - 被检索且命中且没被用户纠正 → trust ↑
- 被检索但用户立即纠正了 → trust ↓
- 长期 trust 低于阈值的 memory,自动 DELETE
这样整个 memory 库会有一个自我演化的能力,老的、错的、过期的记忆会自然下沉,不需要手动维护。
注意事项
- 不要在 tool_call 之间频繁写 memory:每一轮 stop 时统一抽取就够了。频繁写会导致两个问题:
- 一是 fork subagent 的开销叠加,TTFT 变长;
- 二是会写入大量
中间态的过程信息,污染长期记忆。
- 注入 memory 的 token 预算要设上限:给 memory 的注入 token 设一个阈值(比如 2k token),超出就降级到只注入 MEMORY.md 全局摘要。
- Memory ≠ RAG 很多人会把这两个混在一起。区别在于:
- RAG 是检索用户提供的外部知识库(公司文档、PDF、网页)
- Memory 是 Agent 沉淀下来的关于用户的、关于过往交互的主观记忆

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)