




- @weixin_45264425
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
要真正掌握 NumPy,仅了解语法是不够的。多实践:在 Jupyter Notebook 中反复尝试代码,观察结果。阅读官方文档:遇到函数不清楚时,查阅 https://numpy.org/doc/stable/ 是最可靠的方式。分析大型项目:查看 Pandas、Scikit-learn 等库的源码,学习它们如何高效使用 NumPy。刻意练习:尝试用纯 NumPy 实现一些小型算法(如线性回归、P
模型训练逻辑核心优势适合场景CLIP全局排名赛:在所有样本中找最佳匹配零样本能力强,开创性强资源充足(超大算力+大显存),追求开创性研究SigLip成对判断题:只看这对图文是否匹配效率高、批量灵活、效果好实际应用(产品落地)、资源有限、大规模训练简单说:CLIP是“开创者”,SigLip是“优化者”——站在CLIP的肩膀上,用更聪明的训练方式,让多模态模型更高效、更稳定、更易落地。
知识蒸馏就是让轻量化小模型站在大模型的“肩膀上”,不用自己从头摸索,直接学到大模型的深层检测知识,最终实现「小模型的速度,大模型的精度」,是机器人等端侧设备目标检测轻量化的核心方法之一。
模型优化与特定场景。
深度学习是一个人工智能(AI)相关领域,用于教计算机以受人脑启发的方式处理数据。深度学习模型可以识别复杂的图片、文本和声音等数据模式,从而生成准确的见解和预测。神经网络是深度学习的底层技术。它由分层结构中的互连节点或神经元组成。节点在协调的自适应系统中处理数据。它们会就生成的输出交换反馈,从错误中学习,然后持续地改进。因此,人工神经网络是深度学习系统的核心。深度学习和神经网络这两个术语可以互换使用
【数字图像处理笔记】【音频基本知识】【音视频入门知识-- --相关名词、术语、概念】【视频编解码基础|一文了解视频编码过程】【关于音视频的一些知识(demux、filter等)】【详解 YUV 格式(I420/YUV420/NV12/NV12/YUV422)】【HDR基本概念】【视频的编码与传输过程】【CVBS、VGA、HDMI、MIPI等8种视频接口详解】【数字电视-DVB介绍】【视频编解码(十

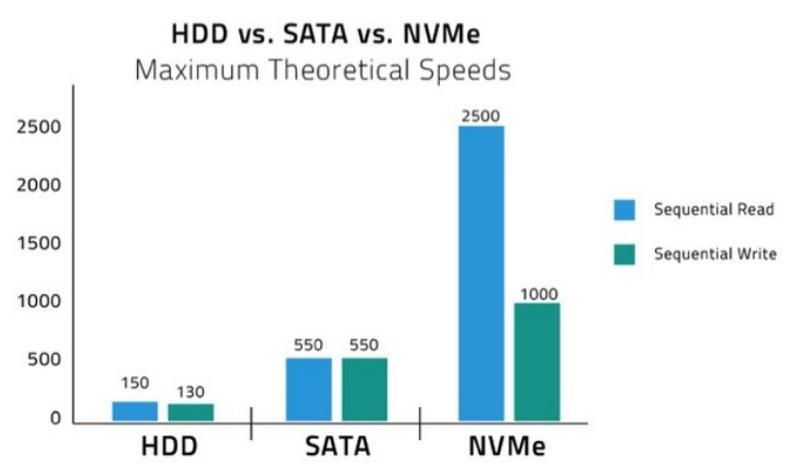
固态硬盘 (SSD) 是基于半导体的存储设备,依靠闪存在计算机系统中存储持久数据。在 SSD 中,每个内存芯片均由包含内存单元(也称为页或扇区)的块构建而成,而内存单元又包含内存位。与使用磁铁存储数据的磁性存储(例如 HDD 和软盘驱动器)不同,固态硬盘使用 NAND 芯片,这是一种非易失性存储技术,不需要任何电源来维护数据。HDD 由于盘片旋转和读/写头移动而具有固有的延迟和访问时间,而 SSD
特征图的每个单元格对应原始图像的一个小方块,

FCN模型先进行一系列的卷积与池化操作,实现图像的下采样,以提取图像中的目标特征,然后再通过反卷积实现上采样,将特征图放大到与原图同样大小的尺寸,并对每个像素点进行分类,从而实现图像的分割。FCN是首个图像语义分割的深度学习模型,它可以实现像素级的分类。FCN也是一个端到端的模型,使用起来非常方便,后来很多分割模型受到了FCN模型的启发。FCN模型会忽略图像的细节信息,同时它也没有考虑图像的全局特
机器学习本质上就是。比如让计算机看1000张猫和狗的照片,它总结出“猫有尖耳朵、狗有大尾巴”的规律后,就能分辨新的照片是猫还是狗。下面用,把核心概念、模型评价、主流算法讲透,保证全面又好懂。