




- @weixin_43275558
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
atomic”同时出现在处理器手册、编程语言、操作系统和并发算法中。它们共享“不可分割”这一核心思想,却不处在同一个抽象层次。在 Arm 体系结构中,atomic 首先描述:一次访问是否会撕裂,一次写以怎样的方式进入多个观察者的视野。编程中的 atomic 则描述:一次 Load、Store、CAS 或加法能否作为一个完整操作参与竞争,编译器和处理器是否共同维持了这种语义。两者不能直接画等号。体系
Linux 中的总线由...这里最关键的是match()和probe()。match()决定一个 device 和一个 driver 是否匹配。PCI bus 根据 vendor/device id 匹配;USB bus 根据 USB id table 匹配;platform bus 可以根据 Device Tree compatible、ACPI id、platform id table、名字匹
本文基于 SylixOS 操作系统,对系统中的 “锁” 和 “信号量” 做一次梳理。
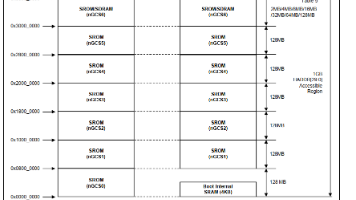
这里说的 “三级引导” 并不是一个固定的、标准的术语,而是想强调,在某些系统里,bootloader 可以再拆得更细,例如。BootROM 不是严格意义上“只能从 ROM 启动操作系统” 的意思,而是指芯片上电复位后,第一段固定的启动程序,通常固化在 ROM(只读存储器)或 mask ROM、OTP ROM,甚至是 eFuse 或者内嵌 Flash 中。可以是单级的,也可以是多级分层的。对 Arm
ARM 架构的应用二进制接口(ABI)为所有原生可执行代码模块制定了一套必须遵循的基础规则,以确保它们能够正确地进行协同工作。在此基础上,针对特定的编程语言(如 C++),ABI 还会提供额外的补充规范。此外,不同的操作系统或运行环境(例如 Linux)为了满足自身的特定需求,也可能会在 ARM ABI 基础规范之上,进一步定义附加的规则。ELF(可执行与可链接格式)
ARMv7-A 处理器的核心竞争力之一,在于它对 **同步异常** 和 **异步中断** 有着一套设计精巧、层级分明、硬件高度自动化的处理机制。理解这套机制,是后续学习操作系统内核、驱动开发、虚拟化以及安全扩展的必备基础。
本文将从**处理器模式**和**核心寄存器**两个维度,系统梳理 ARMv7-A 的编程模型。
本文是 ARM GICv3 学习笔记系列的第一篇,系统梳理 GICv3 的中断类型、硬件架构、状态机模型、亲和性路由、安全模型以及中断处理流程。
这里说的 “三级引导” 并不是一个固定的、标准的术语,而是想强调,在某些系统里,bootloader 可以再拆得更细,例如。BootROM 不是严格意义上“只能从 ROM 启动操作系统” 的意思,而是指芯片上电复位后,第一段固定的启动程序,通常固化在 ROM(只读存储器)或 mask ROM、OTP ROM,甚至是 eFuse 或者内嵌 Flash 中。可以是单级的,也可以是多级分层的。对 Arm
现在这个云时代,云计算渗入我们生活的方方面面。也许你正在使用云服务。但只是你不知道而已。