




- @weixin_42452716
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一、赛事背景医学领域的文献库中蕴含了丰富的疾病诊断和治疗信息,如何高效地从海量文献中提取关键信息,进行疾病诊断和治疗推荐,对于临床医生和研究人员具有重要意义。二、赛事任务本任务分为两个子任务:机器通过对论文摘要等信息的理解,判断该论文是否属于医学领域的文献。提取出该论文关键词。

支持几乎所有 GPU 上对 LLM 预训练或微调,可在 8GB GPU 上微调 7B , Llama3、Mixtral-8x7B、Qwen 等模型, LMDeploy、OpenCompass 集成。支持完整从微调,到部署,评测的一整套工具链。
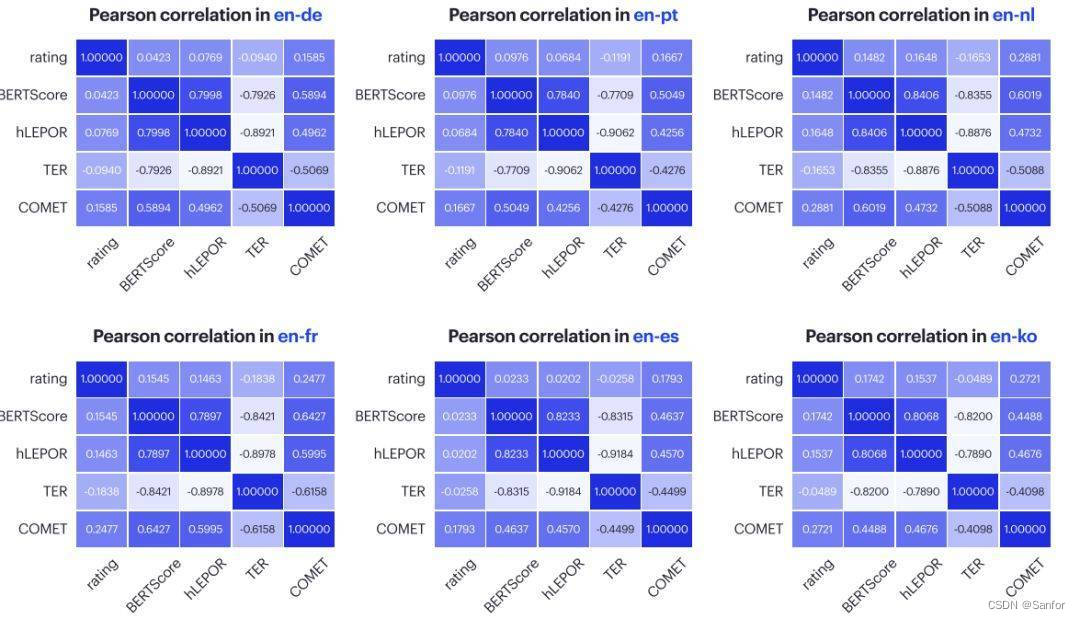
从上述皮尔森相关系数(Pearson correlation coefficient)可以看出,在英-德、英-葡、英-荷、英-法、英-西、英-朝鲜语语言对中, 相比BERTScore、hLEPOR、TER,COMET和人工评测的相关性更接近。近日,Intento公司与e2f公司合作发布《2022年机器翻译评测报告》,从9个行业领域、11个语言对评测了全球市场31个机器翻译引擎。其中,将几个自动评估
分词(tokenization) 是把输入文本切分成有意义的子单元(tokens)。[{‘generated_text’: ‘吕布回·曹操怒�\xa0却说姜维’}]

支持几乎所有 GPU 上对 LLM 预训练或微调,可在 8GB GPU 上微调 7B , Llama3、Mixtral-8x7B、Qwen 等模型, LMDeploy、OpenCompass 集成。支持完整从微调,到部署,评测的一整套工具链。
就是少了文件,https//github.com/studyhub-co/PyMiniRacer,python3.8/site-packages/py_mini_racer/)
import akshare as akimport plotlyimport plotly.offline as plyo# 保存图表,相当于plotly.plotly as py,同时增加了离线功能import plotly.graph_objects as go# 创建各类图表import plotly.figure_factory as ff# 创建tableak_stock_code =
PS: 市面上已经出现不少收费的软件工具, 类似极虎漫剪、速推之类封装好的工具,但其核心功能实现都是一样, 要考验的还是GPT效果;今年出现的Sora相当这个赛道方向的进化版本, 在以后更有可能冲击影视制作领域(UE4)
