- @weixin_41885239
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
什么是神经网络本篇博文仅对深度学习中的几个简单的名字做一个朴素的解释和理解生物神经网络的工作模式神经网络的发现可以说是将人工智能又拔高了一个度,现今很多了不起的成果都是在此之上完成的,那它是如何被发现的呢?既然 是“神经”,自然可以联想到人体里面的的神经,及生物神经。人体中的信息传导都是通过神经元来完成的,所以每个神经元都和其他多个神经元进行连接,信号就这样通过一个神经元接着一个神经元的往下传递,
前言在spark下,有很多种创建dataframe的方法,下面会一一例句from pyspark.sql import SparkSessionfrom datetime import datetime,datefrom pyspark.sql.types import *import pandas as pdfrom pyspark.sql import Rowspark = SparkSess
在训练模型过程中,如果是利用一条一条的数据进行训练的话,收敛速度太慢,所以通常是小批量数据送入模型,然后反向梯度训练模型,那么要达到此效果,就必须利用pytorch提供的Dataloaders数据加载器不断的小批量输出数据给模型,而Dataloader加载器中有一个参数是Dataset,所以必须先初始化Dataset,然后利用Dataset初始化Dataloader。还有一些隐藏的组成,比如每个神
k-means(K均值算法)什么是聚类聚类是无监督学习的一个小分支,其本质就是将样本通过亲近程度对其进行分类,你可能会有疑问?分多少类别?亲近程度如何衡量?分多少类至于分多少类,有的是自动学习得到,比如DBSCAN等,有的是手动指定,比如K-means等。后续的代码中会有体现亲近关系的衡量指标至于用什么来衡量亲近程度?对于有序属性的样本,可以使用闵可夫斯基距离、欧几里得距离、曼哈顿距离来描述,对于
什么是神经网络本篇博文仅对深度学习中的几个简单的名字做一个朴素的解释和理解生物神经网络的工作模式神经网络的发现可以说是将人工智能又拔高了一个度,现今很多了不起的成果都是在此之上完成的,那它是如何被发现的呢?既然 是“神经”,自然可以联想到人体里面的的神经,及生物神经。人体中的信息传导都是通过神经元来完成的,所以每个神经元都和其他多个神经元进行连接,信号就这样通过一个神经元接着一个神经元的往下传递,
在训练模型过程中,如果是利用一条一条的数据进行训练的话,收敛速度太慢,所以通常是小批量数据送入模型,然后反向梯度训练模型,那么要达到此效果,就必须利用pytorch提供的Dataloaders数据加载器不断的小批量输出数据给模型,而Dataloader加载器中有一个参数是Dataset,所以必须先初始化Dataset,然后利用Dataset初始化Dataloader。还有一些隐藏的组成,比如每个神
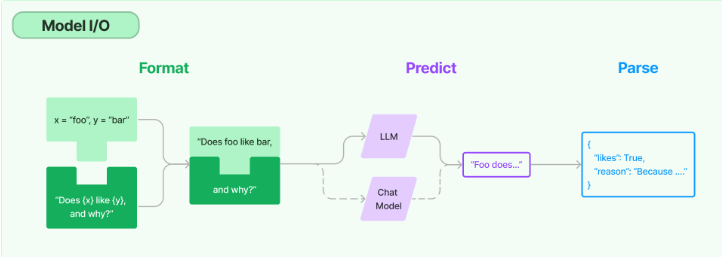
Model I/O模块其实就是提供了语言模型的基础构建接口,那既然是提供构建的接口,我们首先要知道,构建一个模型到底需要哪一些部分。官方给出了一个图例如下:从上面可以看出,在整个工作的流程中,数据通过一定的格式(Format)组织起来,送入到模型中进行预测(Predict),最后将预测结果进行解析(Parse)输出。输入部分语言模型构建部分输出部分。
langchain是一个用于开发以大模型作为底层能力支持的应用的框架,你如果要开发一个基于大模型的的应用,那么选择langchain会方便很多。因为它为大模型应用产品提供了全生命周期管理方案。应用的全生命周期管理2. 应用开发:用langchain提供的组件进行项目开发,或者用langGraph提供有状态的应用开发3. 项目监控:用langsmith提供实时的调试、监控和评估,为项目的迭代提供依据

在训练模型过程中,如果是利用一条一条的数据进行训练的话,收敛速度太慢,所以通常是小批量数据送入模型,然后反向梯度训练模型,那么要达到此效果,就必须利用pytorch提供的Dataloaders数据加载器不断的小批量输出数据给模型,而Dataloader加载器中有一个参数是Dataset,所以必须先初始化Dataset,然后利用Dataset初始化Dataloader。还有一些隐藏的组成,比如每个神
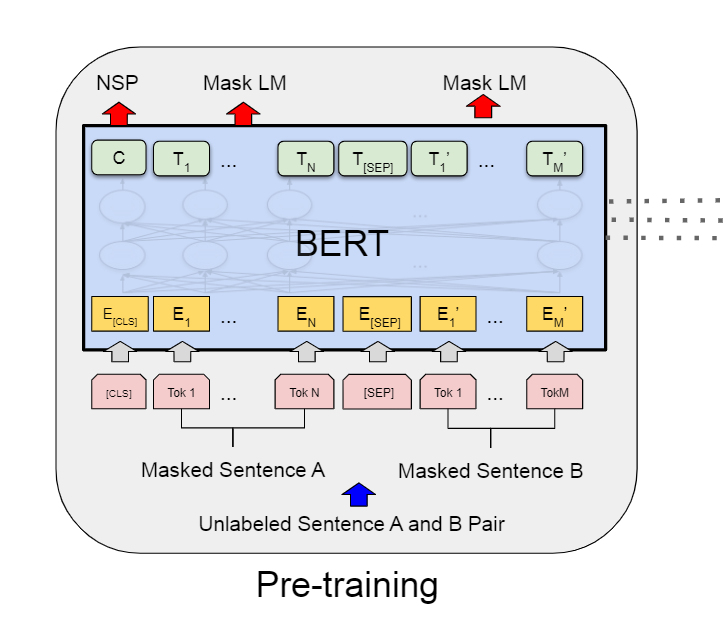
上图就是bert利用了transforemr的编码器结构,从最底层的结构可以看出,E2为原始的单词输入,最中输出的的E2对应的embedding向量T2其实已经综合考虑了上下文信息,因为在神经网络(编码器)内部,信息是交叉,而且特别的是,这个编码器结构恰好实现了和ELMo一样的效果,既能看到单词左边的信息,也能看到单词右边的信息,这就是自注意力的好处。官方虽然没说,但是官方的图展示了,句子的结尾其