




- @weixin_41772761
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在一个已有redis的环境下重新建库或者移动redis dump.rdb出现读取的还是之前存储的数据亦或没有读出数据的情况。1.查看环境存在多少个dump.rdbfind / -name dump.rdb2.确定哪个dump.rdb是想要读取的,查看配置redis中配置文件 redis.conf185行左右确定 dbfilename 名字和 dir 位置如果环境中存在多个du...
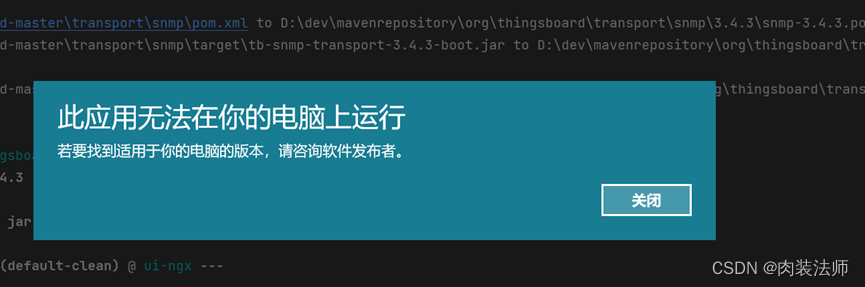
yarn (yarn install) on project ui-ngx: Failed to run task: 'yarn install' failed.
一. 安装oracle client并配置环境下载oracle客户端并解压到本地文件夹https://www.oracle.com/cn/database/technologies/instant-client/winx64-64-downloads.html配置path环境变量将客户端解压地址增加到path种e.g.本人客户端解压地址为 D:\develop\oracleClient\insta
环境:workstation14 linux win10错误描述:win10ping linux能通,winscp连接超时失败。虚拟机网卡选择桥接。防火墙已关没有网络限制、端口限制解决办法:检查虚拟机网卡GateWay设置...
问题描述:爬虫随机生成UA导最新包,包版本已为最新0.1.11pip install fake-useragent执行如下代码并报错from fake_useragent import UserAgentua = UserAgent(cache=False)print(ua.chrome)报错信息Error occurred during loading data. Trying to use c
有一个环境存储不够,当初忘挂载磁盘了[root@siger-master home]# df -h文件系统容量已用可用 已用% 挂载点/dev/mapper/centos-root38G38G20K100% /devtmpfs5.8G05.8G0% /devtmpfs ...
上一节修改好基本配置后,接下来开始安装集群部署所需依赖。
#!/bin/bash#yum install -y sendEmailyum install -y bcItem=测试环境Host=`/usr/bin/hostname`Ip=`ip a | grep 'inet'|awk -F '[ ]' '{print $6}' | grep 24`Cpu=`top -n1 | fgrep "Cpu(s)" | tail -1 | awk -...
首先确保本地hadoop环境正常运行环境:spark 3.0.2| hdfs 3.1.1 | kafka 2.0.0问题描述:执行idea sss读取kafka报错如下Exception in thread "main" java.lang.IllegalArgumentException: Pathname /C:/Users/LZX/AppData/Local/Temp/temporary-e