




- @weixin_41187013
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
#coding:utf-8import tensorflow as tffrom tensorflow import kerasfrom keras import layers"""基于tensorflow框架/mnist数据集,建一个三层全连接神经网络的10分类模型;python代码的简单实现参考文献:Tensorflow文档 函数式API部分https://tensorflow.google.

import pandas as pdimport numpy as np"""kaggle支付反欺诈:IEEE-CIS Fraud Detection第一名方案 特征处理"""###### 1.加载数据df_train = pd.read_csv(r"C:\Users\ld\Desktop\yc18\train1.csv",encoding="cp936")df_test = pd.read_c

本文参考了Kaggle机器学习之模型融合(stacking)心得stacking是用于模型融合的一个大杀器,其基本思想是将多个模型的结果进行融合来提高预测率。,理论介绍有很多,实际的例子比较少,本文将其实例化,并给出详细的代码来说明具体的stacking过程是如何实现的。stacking理论的话可以用下面的两幅图来形象的展示出来。结合上面的图先做一个初步的情景假设,假设采用5折交叉验证:训练集(T
1.TOPSIS法介绍2. 计算步骤(1)数据标准化(2)得到加权后的矩阵(3)确定正理想解和负理想解(4)计算各方案到正(负)理想解的距离(5)计算综合评价值3.实例研究3.1 导入相关库3.2 读取数据3.3 读取行数和列数3.4 数据标准化3.5 得到信息熵3.6 计算权重3.7 计算权重后的数据3.8 得到最大值最小值距离3.9 计算评分总代码。TOPSIS法 —— python_洋洋菜鸟

工作流如下图,首先获取了当前时间,需要注意的是设置正确时区,接下来获取的时间,作为上下文参数输入到大模型节点中,通过提升词,引导大模型根据当前时间,搜索近24小时的新闻,并结构化为新闻简讯文稿,(需要注意的是,该工作流开始节点,未预设输入提示词变量query,直接运行即可!验证结果完全符合,包括时间,真实性,领域等都满足工作流的基本需求,这种通过增加Dify插件实现的资讯获取方式,具有较高的灵活性
用全连接神经网络做多元回归预测的简单实现#coding:utf-8from keras.models import Sequentialfrom keras.layers import Dense, Dropoutfrom sklearn.preprocessing import MinMaxScalerfrom keras.models import load_modelimport panda

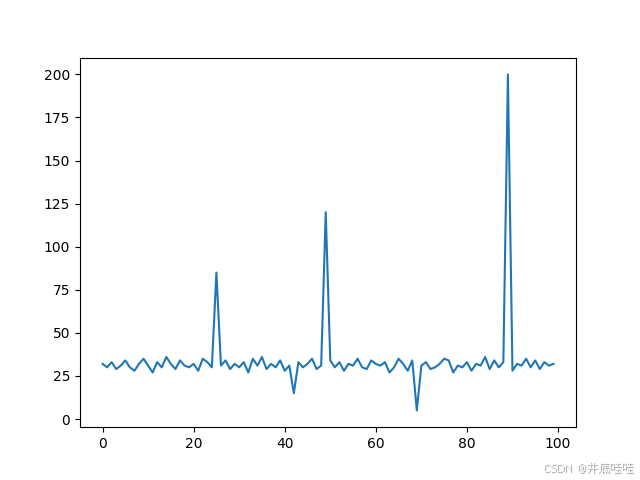
时序数据异常检测是指在时间序列数据中识别出不符合预期模式的点或序列的过程。时序异常基于异常的特性和表现形式,可以分为"点异常","上下文异常","模式异常"三种类型;本文介绍时序数据三种异常类型,及对应检测时序异常的技术路线;1)本文重点:重点研究时序数据异常类型,及相应异常检测技术路线;2)本文缺陷:不探讨具体异常检测方法,由于笔者才疏学浅,如有疏漏敬请指正。
在Python开发环境中,选择合适的镜像源对于确保包的快速和可靠下载至关重要。以下是一些国内主要且广泛使用的Python镜像源地址,以及对每个镜像源的优势的对比;

from __future__ import print_functionimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as smfrom statsmodels.tsa.arima_model import ARIMA"""ARIMA模型Python实现ARIMA模型基本假设:1.数据平稳性2.白
