




- @weixin_41168304
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
多个任务在同一时间段内交替执行。
常用按时间序列排序的一组随机变量X1,X2,...,Xt来表示一个随机时间的时间序列,简记为{Xt};用x1,x2,...,xn或{xt,t=1,2,...,n}表示该随机序列的n个有序观察值,称之为序列长度为n的观察值序列。时间序列分析的目的就是给定一个已经被观测的时间序列,观测该序列的未来值。一、时间序列的平稳性与差分法1.时间序列的平稳性:平稳性就是要求经由样本时间序列所得到的拟合曲线 ,在
根据挖掘目标和数据形式可以建立分类与预测、聚类分析、关联规则、时序模型、离群点检测等模型。首先介绍一下分类与预测模型。一、分类预测模型实现过程分类模型主要是预测分类编号,预测模型主要是建立连续值函数模型,预测给定自变量对应的因变量的值。分类和预测的实现过程类似。以分类算法为例,分类算法主要有两步:第一步是学习步,通过归纳分析训练样本集来建立分类模型,得到分类规则;第二步是分类部,先用已知的测试样本
在数据挖掘过程中,数据预处理过程是占比很大的一部分工作数据预处理过程主要有以下几个部分1、数据清洗——2.数据集成——3.数据变换——4.数据规约本文介绍数据清洗部分一、缺失值分析与处理1.缺失值分析缺失值的影响:(1)数据建模将丢失大量有用信息(2)数据挖掘模型所表现出的不确定性更加显著(3)包含控制的数据会使建模过程陷入混乱,导致不可靠输出缺失值的分析:使用简单的统计分析,可以得到含缺...
多个任务在同一时间段内交替执行。
用python对单一微博文档进行分词——jieba分词(加保留词和停用词)
Adagrad优化算法就是在每次使用一个 batch size 的数据进行参数更新的时候,算法计算所有参数的梯度,那么其想法就是对于每个参数,初始化一个变量 s 为 0,然后每次将该参数的梯度平方求和累加到这个变量 s 上,然后在更新这个参数的时候,学习率就变为。Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那

可以发现上面的 Seq2Seq 方式只是将编码器的最后一个节点的结果进行了输出,但是对于一个序列长度特别长的特征来说,这种方式无疑将会遗忘大量的前面时间片的特征。每个单词(而不是一个字母,也不是一句话)是一个输出,为了满足自然语言的特征,单词与单词之间,是有关联的,不是相互独立的。即输入虽然没有序列,但输出是有序列的。即多个输入,如“我”、“打”、“你”,如果时序关系不同,其含义也是不相同的,即为
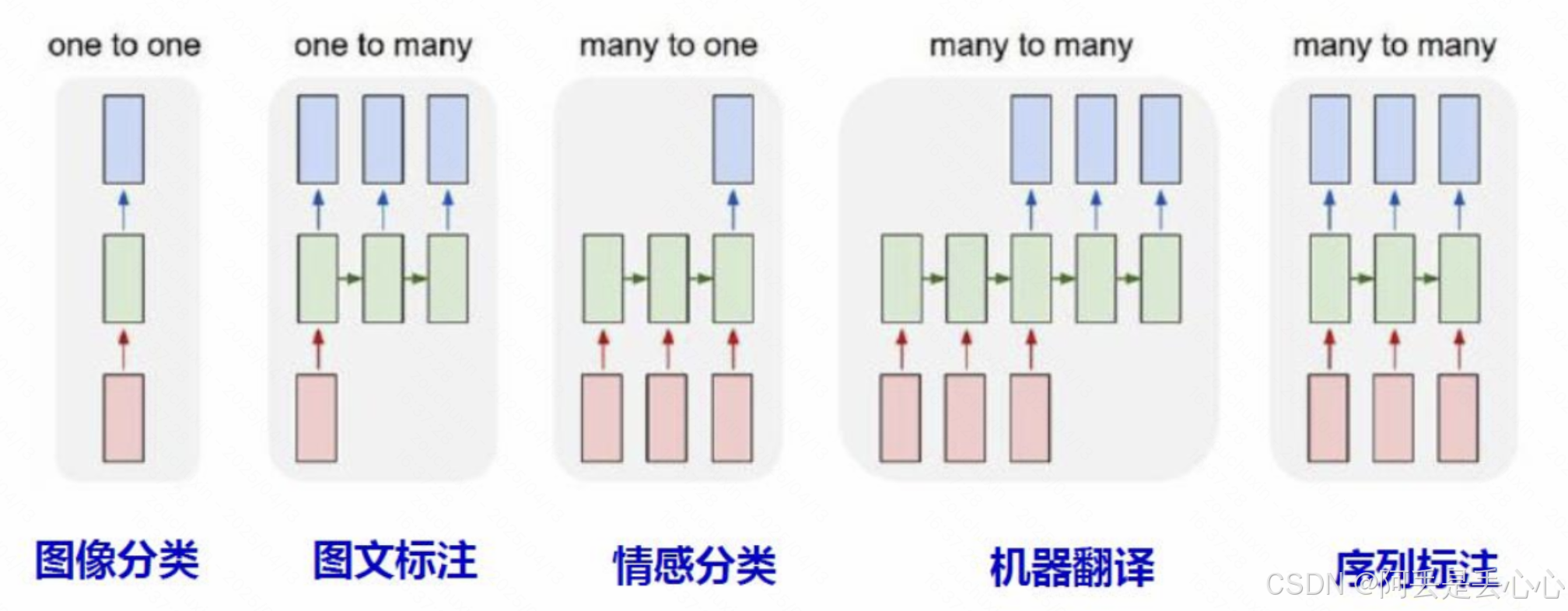
可以发现上面的 Seq2Seq 方式只是将编码器的最后一个节点的结果进行了输出,但是对于一个序列长度特别长的特征来说,这种方式无疑将会遗忘大量的前面时间片的特征。每个单词(而不是一个字母,也不是一句话)是一个输出,为了满足自然语言的特征,单词与单词之间,是有关联的,不是相互独立的。即输入虽然没有序列,但输出是有序列的。即多个输入,如“我”、“打”、“你”,如果时序关系不同,其含义也是不相同的,即为
一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确yi的预测。我们首先将数据集划分为训练集和测试集,由于模型的构建过程中也需要检验模型,检验模型的配置,以及训练程度,过拟合还是欠拟合,所以会将训练数据再划分为两个部分,