




- @weixin_41140174
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,该模型具有训练效果好、不易过拟合等优点。在各种数据挖掘竞赛中也是致命武器,据统计Kaggle上的比赛有一半以上的冠军方案都是基于GBDT。而LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训
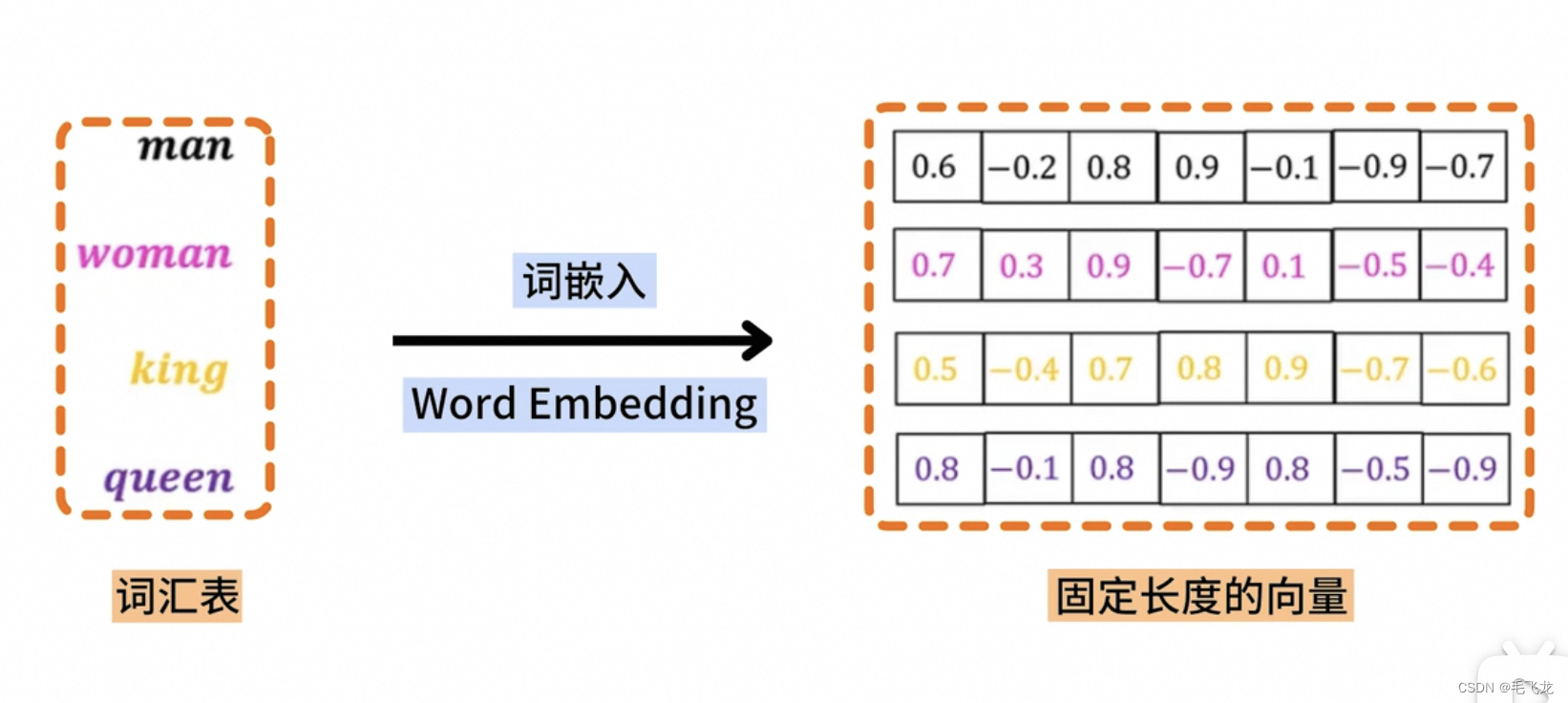
在深度学习领域中,Embedding层扮演着至关重要的角色,尤其在处理文本数据或类别数据。Embedding层的功能有两个:1. 将高维稀疏的输入数据(如单词、类别标签等)转换为低维稠密的向量表示,可以大幅降低数据存储和计算量。2. 低维稠密向量捕获了输入之间的语义和上下文信息,语义相近、类别相近的单词或者类别,其表示向量相似度也高,使得模型能够更好地理解数据信息并进行预测推理。上述两个原因,使得
模型融合方法广泛应用于机器学习中,其原因在于,将多个学习器进行融合预测,能够取得比单个学习器更好的效果,实现“三个臭皮匠,顶一个诸葛亮”,其原因在于通过模型融合,能够降低预测的偏差和方差。本文对模型融合中常见的三种方法进行一个简要介绍:包括Bagging、Boosting、Stacking.........
深度学习网络的训练可能会很慢、也可能无法收敛,本文介绍使用keras进行深度神经网络训练的加速技巧,包括解决梯度消失和爆炸问题的策略(参数初始化策略、激活函数策略、批量归一化、梯度裁剪)、重用预训练层方法、更快的优化器算法,以及学习率的调度策略。

内容参考自:ML-NLP/Machine Learning/3.Desition Tree at master · NLP-LOVE/ML-NLP · GitHub,有修改1. 什么是决策树1.1 决策树的基本思想其实用一下图片能更好的理解LR模型和决策树模型算法的根本区别,我们可以思考一下一个决策问题:是否去相亲,一个女孩的母亲要给这个女海介绍对象。大家都看得很明白了吧!LR模型是一股脑儿的把所
提升树(Boosting Tree)是以分类树或者回归树位基本分类器到提升方法,提升树被认为是统计学习中性能最好的方法之一Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重(Ada Boosting),或者让新的预测器对前一个预测器到残差进行拟合(GBDT)。预测时,根据各层分类
在深度学习领域中,Embedding层扮演着至关重要的角色,尤其在处理文本数据或类别数据。Embedding层的功能有两个:1. 将高维稀疏的输入数据(如单词、类别标签等)转换为低维稠密的向量表示,可以大幅降低数据存储和计算量。2. 低维稠密向量捕获了输入之间的语义和上下文信息,语义相近、类别相近的单词或者类别,其表示向量相似度也高,使得模型能够更好地理解数据信息并进行预测推理。上述两个原因,使得
对于IDEA集成开发环境,运行Python代码时需要配置Python解释器,没有正确配置时,直接运行代码会报错,例如:import pandas as pd ModuleNotFoundError: No module named pands.Anaconda是一款非常流行的Python数据分析工具,本文介绍在IDEA集成开发环境中配置Anaconda的python解释器对于已经存在的项目,设置I
深度学习网络的训练可能会很慢、也可能无法收敛,本文介绍使用keras进行深度神经网络训练的加速技巧,包括解决梯度消失和爆炸问题的策略(参数初始化策略、激活函数策略、批量归一化、梯度裁剪)、重用预训练层方法、更快的优化器算法,以及学习率的调度策略。
提升树(Boosting Tree)是以分类树或者回归树位基本分类器到提升方法,提升树被认为是统计学习中性能最好的方法之一Boosting方法训练基分类器时采用串行的方式,各个基分类器之间有依赖。它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重(Ada Boosting),或者让新的预测器对前一个预测器到残差进行拟合(GBDT)。预测时,根据各层分类