




- @weixin_39653948
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了如何通过强化学习 (RL)——一种常用的大型模型微调技术——进一步改进这些 VLA 模型。然而,将在线 RL 直接应用于 VLA 模型会带来重大挑战,包括训练不稳定性(严重影响大型模型的性能)和计算负担(超过大多数本地机器的能力)。为了应对这些挑战,提出了 iRe-VLA 框架,该框架在RL和监督学习之间迭代,有效地改进 VLA 模型,利用 RL 的探索优势,同时保持监督学习的稳定性。

计算机视觉必读论文图像分类,目标检测,GAN,GNN,OCR等,全文中英对照翻译,相关术语,代码等。
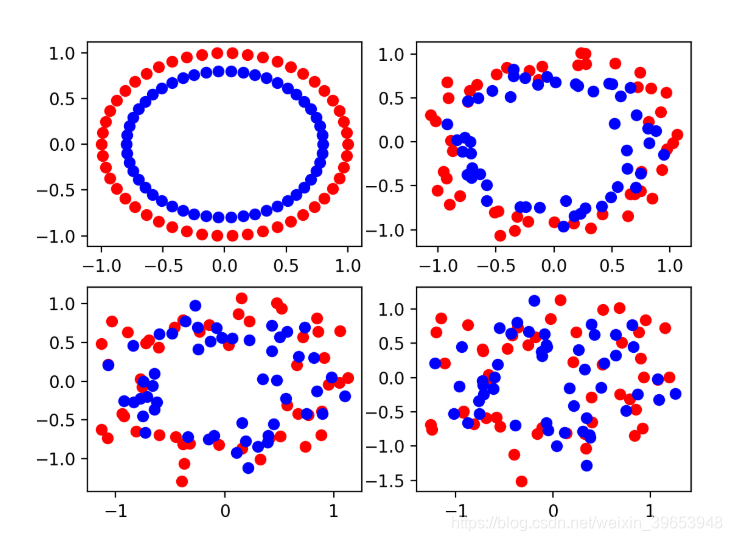
本文介绍了数据集的大小对模型性能的影响。包括训练集大小对测试准确率的影响和测试集大小对测试准确率的影响。
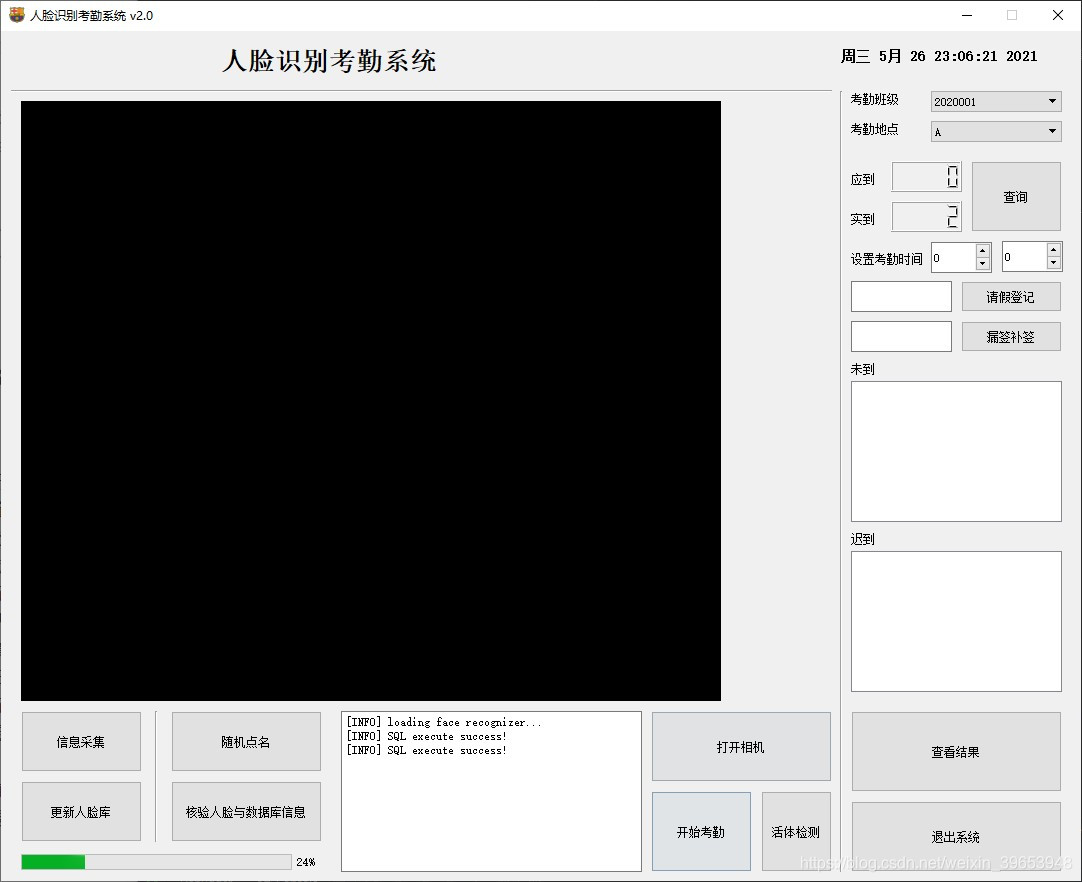
本项目使用Python3.8编写,Qt Designer(QT5)设计主界面,PyQt5库编写控件的功能,使用开源FaceNet人脸识别算法进行人脸识别,使用眨眼检测来实现活体识别,使用OpenCV3实现实时人脸识别。同时,将班级学生信息,各班级学生人数、考勤信息录入到MySQL数据库中,方便集中统一化管理。因为本项目仅由我一个人开发,能力精力有限,实现了预期的绝大多数功能,但是活体检测功能还存在
本文探讨了如何通过强化学习 (RL)——一种常用的大型模型微调技术——进一步改进这些 VLA 模型。然而,将在线 RL 直接应用于 VLA 模型会带来重大挑战,包括训练不稳定性(严重影响大型模型的性能)和计算负担(超过大多数本地机器的能力)。为了应对这些挑战,提出了 iRe-VLA 框架,该框架在RL和监督学习之间迭代,有效地改进 VLA 模型,利用 RL 的探索优势,同时保持监督学习的稳定性。
本项目使用Python3.8编写,Qt Designer(QT5)设计主界面,PyQt5库编写控件的功能,使用开源FaceNet人脸识别算法进行人脸识别,使用眨眼检测来实现活体识别,使用OpenCV3实现实时人脸识别。同时,将班级学生信息,各班级学生人数、考勤信息录入到MySQL数据库中,方便集中统一化管理。因为本项目仅由我一个人开发,能力精力有限,实现了预期的绝大多数功能,但是活体检测功能还存在
本文详细总结了近几年时间/时空序列分类/预测/异常检测模型顶会论文,包括Transformer及其变体。

本文提出了RECAP方法,旨在通过强化学习提升视觉-语言-动作(VLA)模型在真实世界的性能 。该方法利用价值函数评估混合数据(演示、自主探索、人工干预)的质量,并通过优势调节(Advantage Conditioning)引导策略优化 。实验表明,pi0.6*$模型在叠衣物、组装纸箱等复杂长程任务中,吞吐量翻倍且故障率减半,验证了VLA从经验中持续学习的有效性 。
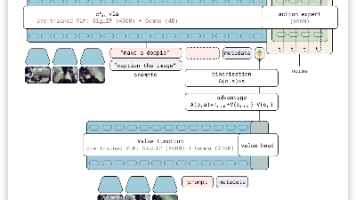
针对VLA模型微调中连续动作头梯度破坏VLM语义知识的问题,本文提出“知识隔离”训练策略 。通过阻断Action Expert对主干的梯度回传,并结合离散动作预测进行表征学习,该方法有效避免了灾难性遗忘 。实验显示,其训练收敛速度比pi0快7.5倍,推理高效且语言遵循能力强,在LIBERO基准上达成SOTA,成功兼顾了通用语义智能与高频精准控制 。

针对VLA模型微调中连续动作头梯度破坏VLM语义知识的问题,本文提出“知识隔离”训练策略 。通过阻断Action Expert对主干的梯度回传,并结合离散动作预测进行表征学习,该方法有效避免了灾难性遗忘 。实验显示,其训练收敛速度比pi0快7.5倍,推理高效且语言遵循能力强,在LIBERO基准上达成SOTA,成功兼顾了通用语义智能与高频精准控制 。