




- @weixin_37899718
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了AI测试技能包中的性能压测和视觉巡检方案。性能压测采用"一份spec生成三种脚本(k6/JMeter/Locust)"的模式,通过声明式配置降低门槛,并构建分析-规划-执行-报告四阶段流水线。视觉巡检通过Playwright全站截图生成HTML报告,作为上线前的视觉兜底。两者共同组成发布前的"双保险":压测保障性能指标,截图保障UI展示。文章还分享

现在都要求AI提效,大家肯定也用过通用AI工具写测试脚本,结果它每次给的代码都不一样,同一个接口今天用 requests、明天用 httpx,断言风格也不统一。更崩溃的是,老员工一走,他积累的那些测试经验——哪个接口容易超时、哪个参数容易越界、哪个场景容易漏测——就跟着人一起走了。这是我的一整套skills,21 个目录、133 个文档、15 个可执行脚本,我叫它"AI 测试技能包"。这篇文章,我

本文介绍了LLM版本升级时的回归测试方法论。通过电商数据分析智能体案例,展示了qwen-plus到qwen3.5-plus升级时30%用例行为发生变化的情况。提出了三层测试体系:黄金用例集(30-50个核心功能用例)、参考用例集(50-100个非核心用例)和探索用例集(新场景测试)。重点阐述了行为差异检测方法,包括版本对比看板、Diff报告生成和灰度发布策略。提供了黄金用例集模板、Python实现

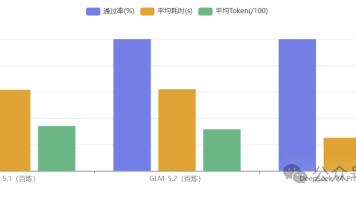
本次评测对比了GLM-5.1、GLM-5.2和DeepSeek-V4-Pro三个大模型在10项真实测试任务中的表现。结果显示:三个模型均实现100%任务通过率,质量接近;但DeepSeek-V4-Pro在效率上优势显著,平均耗时25.2秒(比GLM-5.1快59%),平均Token消耗2092(节省38.7%)。评测涵盖用例生成、脚本编写、性能分析等测试工程全链路任务,发现国产模型已具备实用能力,

本次评测对比了GLM-5.1、GLM-5.2和DeepSeek-V4-Pro三个大模型在10项真实测试任务中的表现。结果显示:三个模型均实现100%任务通过率,质量接近;但DeepSeek-V4-Pro在效率上优势显著,平均耗时25.2秒(比GLM-5.1快59%),平均Token消耗2092(节省38.7%)。评测涵盖用例生成、脚本编写、性能分析等测试工程全链路任务,发现国产模型已具备实用能力,
文章摘要: 测试员周周对GLM-5.1、GLM-5.2和DeepSeek-V4-Pro三款大模型进行了真实场景评测,覆盖10项测试工程任务。结果显示: 通过率:三模型均达100%,输出质量接近; 效率:DeepSeek-V4-Pro显著领先,平均耗时25.2秒(比GLM-5.1快59%),Token消耗减少38.7%; 成本:DeepSeek估算成本最低(0.84元/万Token)。 核心结论:国
本文探讨了智能体性能测试的关键维度,通过真实电商场景案例揭示了仅功能测试的不足。文章提出性能测试三大核心指标:1)延迟(需关注P50/P90/P99分位数),2)Token预算(直接影响成本,需建立消耗模型),3)并发能力(高负载下的稳定性)。测试数据显示,典型任务如销售报告生成的平均延迟达45秒,Token消耗约8000(成本0.5元/次),并发性能随请求量显著下降。作者提供了完整测试方案(含P

文章摘要:本文探讨了智能体在多轮对话测试中的表现衰减现象及其评估方法。研究发现,智能体的记忆能力随对话轮数增加呈阶梯式衰减:3轮内准确率100%,5轮降至80%,8轮45%,12轮仅20%。文章提出五维评估框架:信息记忆(半衰期模型)、指代消解(阶跃式退化)、话题切换、冲突处理和语义漂移,并开发了支持模糊匹配的MemoryRecallScore评分算法(0-1分制)。测试数据显示,在固定窗口策略下

《真实业务场景下的测试实战:电商进销存系统全链路训练方案》 摘要: 针对测试人员自学过程中缺乏真实业务场景的痛点,作者开发了一套企业级电商进销存财务一体化系统。该系统涵盖商品管理、秒杀系统、采购销售、库存财务等完整业务链路,采用前后端分离架构(Vue3+Flask+MySQL+Redis),通过Docker一键部署。每个模块对应核心测试技能训练:商品CRUD练接口测试、秒杀系统练性能测试(含6种防

本文摘要: 针对大语言模型(LLM)在电商场景中的幻觉和安全隐患,提出系统化测试方案。知识测试涵盖事实性(准确率)、推理(正确率)和幻觉检测(虚构问题编造率),实测显示未优化的模型幻觉率高达70%。安全测试聚焦四类攻击:有害内容、隐私泄露、Prompt注入和Jailbreak,关键发现包括:规则过滤对已知攻击拦截率100%,但需结合LLM检测应对变体攻击。交付物包含标准测试集(如30个事实问题、2
