




- @weixin_35154281
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
深度排序模型通过召回的操作, 我们已经进行了问题规模的缩减, 对于每个用户, 选择出了N篇文章作为了候选集,并基于召回的候选集构建了与用户历史相关的特征,以及用户本身的属性特征,文章本省的属性特征,以及用户与文章之间的特征,下面就是使用机器学习模型来对构造好的特征进行学习,然后对测试集进行预测,得到测试集中的每个候选集用户点击的概率,返回点击概率最大的topk个文章,作为最终的结果。排序阶段选择了
工业蒸汽预测赛题背景火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。赛题描述经脱
新闻推荐之特征工程目标:制作特征和标签, 转成监督学习问题我们先捋一下基于原始的给定数据, 有哪些特征可以直接利用:文章的自身特征, category_id表示这文章的类型, created_at_ts表示文章建立的时间, 这个关系着文章的时效性, words_count是文章的字数, 一般字数太长我们不太喜欢点击, 也不排除有人就喜欢读长文。文章的内容embedding特征, 这个召回的时候用过
GAN 生成动漫头像什么是GAN? 生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习]最具前景的方法之一。GAN的核心思想来源于博弈论的纳什均衡,它设定参与游戏双方分别为一个生成器和一个判别器,生成器的目的是尽量去学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器...
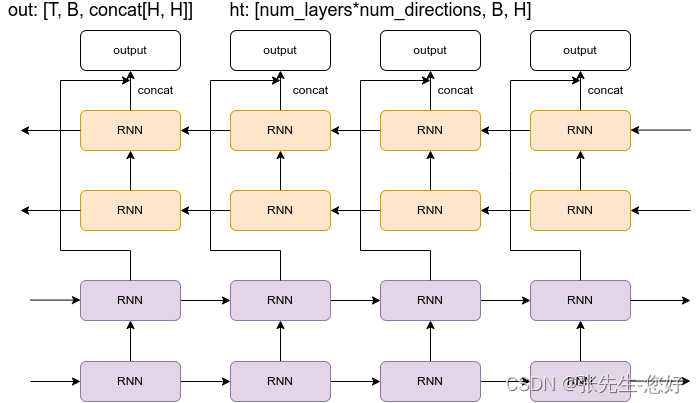
LSTM输出输出维度图示文章目录LSTM输出输出维度图示单向单层单向多层双向单层双向多层参考单向单层# 构造RNN网络,x的维度5,隐层的维度10,网络的层数2rnn_seq = nn.RNN(5, 10, 1)# 构造一个输入序列,句长为 6,batch 是 3, 每个单词使用长度是 5的向量表示# 输入维度为:[seq_len,batch_size,output_dim]x = torch.r
转载:协同过滤算法UserCF和ItemCF优缺点对比UserCF:性能:适用于用户较少的场合,如果用户很多,计算用户相似度矩阵代价很大。领域:时效性较强,用户个性化兴趣不太明显的领域。实时性:用户有新行为,不一定造成推荐结果的立即变化。冷启动:在新用户对很少的物品产生行为后,不能立即对它进行个性化推荐,因为用户相似度表示每隔一段时间离线计算的。新物品上线后一段时间,一旦有用户对物品产生行为,就可
Python画图新罗马字体调整本文主要依据参考连接一完成,实际效果表明可行,推荐阅读未改变字体import matplotlib as mplimport matplotlib.pyplot as plt# 设置西文字体为新罗马字体from matplotlib import rcParamsconfig = {#"font.family":'Times New Roman',# 设置字体类型"f
PySpark之SparkMLlib基本操作前言Spark的引入:传统的机器学习算法,由于技术和单机存储的限制,只能在少量数据上使用,依赖于数据抽样大数据技术的出现,可以支持在全量数据上进行机器学习机器学习算法涉及大量迭代计算基于磁盘的MapReduce不适合进行大量迭代计算基于内存的Spark比较适合进行大量迭代计算Spark的优点:Spark提供了一个基于海量数据的机器学习库,它提供了常用机器