




- @victor_manches
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Dify 之前有介绍过。

本次以英雄联盟对局胜负预测任务为基础,要求实现决策树算法相关细节,加深对算法的理解,并了解做机器学习任务的大致流程。英雄联盟(League of Legends,LoL)是一个多人在线竞技游戏,由拳头游戏(Riot Games)公司出品。在游戏中,每位玩家控制一位有独特技能的英雄,红蓝两支队伍各有五位玩家进行对战,目标是摧毁对方的基地水晶。水晶有多座防御塔保护,通常需要先摧毁一些防御塔再摧毁水晶。

随着电商平台的兴起,以及疫情的持续影响,线上购物在我们的日常生活中扮演着越来越重要的角色。在进行线上商品挑选时,评论往往是我们十分关注的一个方面。然而目前电商网站的评论质量参差不齐,甚至有水军刷好评或者恶意差评的情况出现,严重影响了顾客的购物体验。因此,对于评论质量的预测成为电商平台越来越关注的话题,如果能自动对评论质量进行评估,就能根据预测结果避免展现低质量的评论。本案例中我们将基于集成学习的方
本次案例中,你需要用python实现Softmax回归方法,用于MNIST手写数字数据集分类任务。你需要完成前向计算loss和参数更新。你需要首先实现Softmax函数和交叉熵损失函数的计算。在更新参数的过程中,你需要实现参数梯度的计算,并按照随机梯度下降法来更新参数。
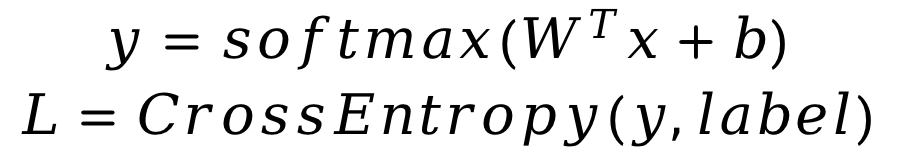
电子邮件是互联网的一项重要服务,在大家的学习、工作和生活中会广泛使用。但是大家的邮箱常常被各种各样的垃圾邮件填充了。有统计显示,每天互联网上产生的垃圾邮件有几百亿近千亿的量级。因此,对电子邮件服务提供商来说,垃圾邮件过滤是一项重要功能。而朴素贝叶斯算法在垃圾邮件识别任务上一直表现非常好,至今仍然有很多系统在使用朴素贝叶斯算法作为基本的垃圾邮件识别算法。本次实验数据集来自Trec06。
使用vscode 用git 拉取代码,提示:在签出前,请清理存储库工作树**git仓库上的代码和本地代码存在冲突了所以会报这个报错。
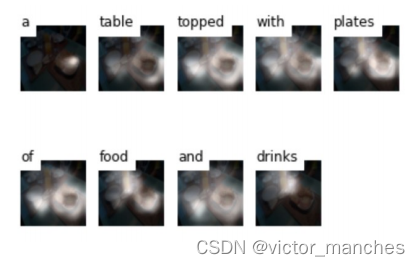
本次案例将使用深度学习技术来完成图像自然语言描述生成任务,输入一张图片,模型会给出关于图片内容的语言描述。本案例使用coco2014数据集[1],包含82,783张训练图片,40,504张验证图片,40,775张测试图片。案例使用Andrej Karpathy[2]提供的数据集划分方式和图片标注信息,案例已提供数据处理的脚本,只需下载数据集和划分方式即可…本次案例将使用深度学习技术来完成图像自然语
本次案例中,你需要用python实现Softmax回归方法,用于MNIST手写数字数据集分类任务。你需要完成前向计算loss和参数更新。你需要首先实现Softmax函数和交叉熵损失函数的计算。在更新参数的过程中,你需要实现参数梯度的计算,并按照随机梯度下降法来更新参数。
课程链接:驭风计划是由清华大学老师教授的,其分为四门课,包括: 机器学习(张敏教授) , 深度学习(胡晓林教授), 计算机语言(刘知远教授) 以及数据结构与算法(邓俊辉教授)。本人是综合成绩第一名,除了数据结构与算法其他单科均为第一名。代码和报告均为本人自己实现,由于篇幅限制,只展示任务布置以及关键代码,如果需要报告或者代码可以私聊博主部分授课老师为邓俊辉教授,主要通过从贪心,分治,图搜索,动态规

课程链接:驭风计划是由清华大学老师教授的,其分为四门课,包括: 机器学习(张敏教授) , 深度学习(胡晓林教授), 计算机语言(刘知远教授) 以及数据结构与算法(邓俊辉教授)。本人是综合成绩第一名,除了数据结构与算法其他单科均为第一名。代码和报告均为本人自己实现,由于篇幅限制,只展示任务布置以及关键代码,如果需要报告或者代码可以私聊博主部分授课老师为邓俊辉教授,主要通过从贪心,分治,图搜索,动态规
