




- @u011426236
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenCode 接本地 Ollama 模型时,如果工具调用总是“看起来会、实际上不会”,非常有可能不是模型不行,而是上下文长度太小。最终把上下文提到 64k 之后,问题才终于恢复正常。回头看,这个坑真的很浪费时间,但也确实值得记下来——因为它太像“模型能力问题”了,实际上却是“运行参数问题”。
OpenCode 接本地 Ollama 模型时,如果工具调用总是“看起来会、实际上不会”,非常有可能不是模型不行,而是上下文长度太小。最终把上下文提到 64k 之后,问题才终于恢复正常。回头看,这个坑真的很浪费时间,但也确实值得记下来——因为它太像“模型能力问题”了,实际上却是“运行参数问题”。
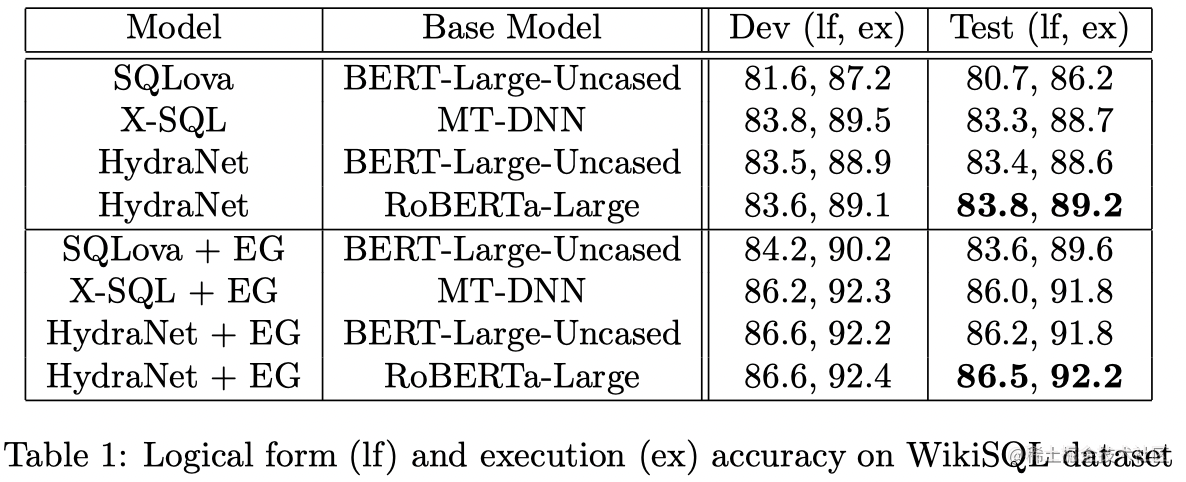
HybridSQL将Text-to-SQL定义为一个多任务学习问题,可以通过适应预先训练的Transformer模型来解决。X-SQL中,模型直接对全表进行了序列化处理,在后续预测子任务中,需要进行Attentive pooling。如下图所示,HydraNet的一个创新点在于它将表示层的输入变成了每个列的列文本和query文本组成的对,这样对于每个列都是bert标准的sentence pair输
神经网络机器翻译(Neural Machine Translation)这节课我们利用RNN来做机器翻译,机器翻译模型有很多种,这节课我们介绍Seq2Seq模型,把英文翻译为德文。机器翻译是一个Many to Many的问题。首先,我们要处理数据。机器翻译数据(Machine Translation Data)这里,我们仅是学习需要,使用一个小规模数据集即可。可以使用http://www.many
昨晚Qwen3发布了完整的技术报告,介绍了最新的 Qwen3 系列模型,包含稠密架构和 MoE 架构,参数规模从 0.6B 到 235B。Qwen3 将“思考模式”(用于复杂、多步推理)和“非思考模式”(用于快速、上下文驱动的响应)整合入统一框架,无需切换模型。同时引入“思考预算”机制,用户可自适应地分配计算资源。实验评估表明,Qwen3 在代码生成、数学推理、智能体任务等多个基准测试上取得了业界
Kimi在近期发布了最大规模开源模型K2,其为MOE架构,包含1.04T参数,32B激活。K2 重点强调了其大规模的智能体(agentic)数据合成流水线和联合强化学习方法,模型通过与真实和合成环境的交互来增强其能力。实验评测显示,K2在agentic 能力和编程、数学、推理能力上均在开源非思考模型中取得最佳性能表现。
消息流中的错误无论怎么试都无法继续使用。后续检索发现是限额问题,于是便搜集整理了一下目前的ChatGPT模型限额的相关信息,特此记录。
问题说明项目需要,要加载一个具有两千多万条样本的两万多分类问题的数据集在BERT模型上进行Fine tune,我选取了其中2%的数据(约50万条)作为测试集,然后剩下的两千多万条作为训练集。我按照 Transformers库官方文档里的 Fine-tuning with custom datasets一文中对BERT模型在IMDb数据集上Fine tune的过程进行改写。原代码如下:train_t
阿里通义实验室提出WebDancer——一套从数据构建到训练策略的端到端信息检索智能体构建范式,支持多轮、多工具交互与长程推理。该系统在 GAIA与 WebWalkerQA 等复杂多跳信息检索任务中表现优异,验证其方法有效性与可扩展性。
WebSailor 是一套开源智能体训练方法,旨在提升其在复杂信息检索任务中的超人类推理能力。现有开源网页智能体在 BrowseComp-en/zh 等任务中几乎无法作答,其原因在于缺乏应对高不确定性、缺乏预定义路径任务的推理能力。WebSailor 通过高不确定性任务构造、RFT 冷启动、强化学习算法 DUPO 的集成流程,显著提升了模型在复杂搜索任务中的能力,性能首次与专有系统接近。