




- @u011239443
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
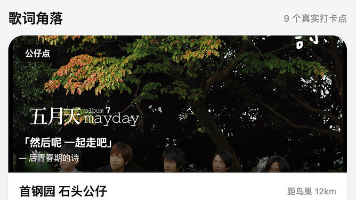
独立开发者利用TRAE AI开发的"MaydayLand·五月天城市漫游"H5应用,为五月天粉丝打造了一个集城市角落打卡、同好社交和主题游戏于一体的移动端平台。该产品通过歌词角落地图、暗号打卡、Canvas生成专属卡片等功能,解决了五迷寻找同好据点的需求,并内置8款五月天主题小游戏和资讯自动更新系统。项目采用Flask+原生前端技术栈,在ModelScope平台部署,展现了AI辅助开发在实现复杂功
http://blog.csdn.net/u011239443/article/details/763602941 基础概念1.1 熵、联合熵、条件熵、交叉熵与相对熵的意义?1.2 归一化方法?1、线性函数归一化(Min-Max scaling)线性函数将原始数据线性化的方法转换到[0 1]的范围,归一化公式如下:2、0均值标准化(Z-score sta...
http://blog.csdn.net/u011239443/article/details/52623602《An Overview of Data Warehousing and OLAP Technology》摘要数据仓库和联机分析处理(OLAP)是决策支持基本要素,已经日益成为数据库行业的重点。许多商业产品和服务现已推出,并且所有主要的数据库管理系统供应商现在已经在这些领域提供产品。决
想要提高模型的性能有时会是一件难度不小的事情。如果你也遇到过类似的情况,相信一定会认同我这一看法。在一一尝试毕生所学的对策和算法之后,依然没能够提高模型的准确率,这时,一种陷入困境的无助感就会涌上心头。事实上,百分之九十的数据科学家就是在这一阶段选择了放弃。但是,好戏这才开始!正是这一点划清了平凡的数据科学家与非凡的数据科学家的界限。你是不是也梦想着成为一名卓越的数据科学家呢?如果是的话,你就需要
http://blog.csdn.net/u011239443/article/details/763602941 基础概念1.1 熵、联合熵、条件熵、交叉熵与相对熵的意义?1.2 归一化方法?1、线性函数归一化(Min-Max scaling)线性函数将原始数据线性化的方法转换到[0 1]的范围,归一化公式如下:2、0均值标准化(Z-score sta...
MapReduce Shuffle原理 与 Spark Shuffle原理MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。为什么MapReduce计算模型需要Shuffle过程?我们都知
原文:https://blog.csdn.net/liuchonge/article/details/78749623文章亮点本文是使用深度增强学习DRL的方法来解决多轮对话问题。首先使用Seq-to-Seq模型预训练一个基础模型,然后根据作者提出的三种Reward来计算每次生成的对话的好坏,并使用policy network的方法提升对话响应的多样性、连贯性和对话轮次。文章最大的亮点就在于定..
http://blog.csdn.net/u011239443/article/details/790570161.1 计算机视觉计算机视觉领域的问题图片分类目标检测图片风格转化深度学习在图像中的应用过多的权重参数矩阵让计算、内存消耗使得传统神经网络不能接受。1.2 边缘检测示例过滤器示例该过滤器为竖直边缘过滤器。为什么叫
NLP《A Neural Conversational Model)》(对话机器人)【笔记】《Bag of Tricks for Efficient Text Classification》(fastText)【笔记】《Convolutional Neural Networks for Sentence Classification》(TextCnn)【笔记】《Attention ...
http://blog.csdn.net/u011239443/article/details/763602941 基础概念1.1 熵、联合熵、条件熵、交叉熵与相对熵的意义?1.2 归一化方法?1、线性函数归一化(Min-Max scaling)线性函数将原始数据线性化的方法转换到[0 1]的范围,归一化公式如下:2、0均值标准化(Z-score sta...