




- @u010402786
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
某国家一级演员在微博平台控诉的其影视素材及公益禁毒短片遭到恶意“搬运”,侵权者利用极低门槛的AI合成工具,仅凭3分钟视频素材,便直接篡改其声音与口型,生成高度逼真的虚假商业推广内容。针对内容标识、数据溯源、算法偏见矫正等关键环节,提供具体、可测试的技术要求与验证方法,为研发提供明确标尺,使合规评估客观统一,促进技术与法务业务协同。标准配套合规自查清单、评估报告模板等实用工具,将条款转化为可即时上手

提高人脸检测正确率,如何使用Opencv中自带的人脸分类器
Faster rcnn是用来解决计算机视觉(CV)领域中Object Detection的问题的。最初的检测分类的解决方案是:Hog+SVM来实现的;深度学习中经典的解决方案是使用: RCNN
过拟合 梯度弥散 batchsize 不平衡数据集
卷积神经网络改进
具身智能行业,太需要一个真正能打、真正能用、真正开源的通用大脑了。随着宇树G1在春晚舞台大展拳脚,具身智能的竞争也从硬件军备赛迈入了大脑进化战。在近半年的时间内,中国力量集体爆发,宇树、小米、阿里、自变量、千寻、星海图等团队,相继开源各自的VLA具身大模型。本文将拆解这几大国产开源模型的硬核实力,看谁在卷操作精度,谁在卷实时反应,谁又在卷工业落地!原文链接:六大开源VLA模型。

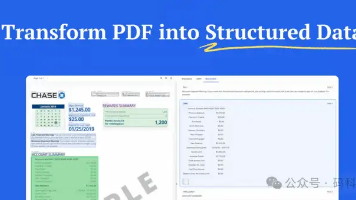
如果你正在被复杂的文档解析困扰,或者想提升企业知识库的召回准确率,建议去TextIn官网申请一个试用Key,挑一篇你们最复杂的PDF,跟着实战手册跑一遍。信心满满推到生产,一接入真实业务文档——需要合并的表格乱合并对不齐,字母解析出来变成了数字,目录、正文、页眉页脚都混在一起、印章变成了黑方块……在基础文档结构化知识库的基础上,增加“决策”与“外扩”两个节点,大模型不再局限于对本地文档的简单总结与
在四个工业异常检测基准上进行评估,并将模型与基于MLLM和CLIP的方法进行比较,包括专有模型、开源VLM、微调的GRPO系统和基于提示的CLIP变体(AnomalyCLIP、UniVAD)。这种基于工具的多轮推理过程使智能体能够首先定位模糊区域,然后检索参考知识,最后得出可靠、可解释的结论——实现了比非工具单轮推理显著更高的准确性。而工业缺陷通常是细微的、异质的,并且位于杂乱背景的小区域内,这使

具身智能行业,太需要一个真正能打、真正能用、真正开源的通用大脑了。随着宇树G1在春晚舞台大展拳脚,具身智能的竞争也从硬件军备赛迈入了大脑进化战。在近半年的时间内,中国力量集体爆发,宇树、小米、阿里、自变量、千寻、星海图等团队,相继开源各自的VLA具身大模型。本文将拆解这几大国产开源模型的硬核实力,看谁在卷操作精度,谁在卷实时反应,谁又在卷工业落地!原文链接:六大开源VLA模型。
具身智能行业,太需要一个真正能打、真正能用、真正开源的通用大脑了。随着宇树G1在春晚舞台大展拳脚,具身智能的竞争也从硬件军备赛迈入了大脑进化战。在近半年的时间内,中国力量集体爆发,宇树、小米、阿里、自变量、千寻、星海图等团队,相继开源各自的VLA具身大模型。本文将拆解这几大国产开源模型的硬核实力,看谁在卷操作精度,谁在卷实时反应,谁又在卷工业落地!原文链接:六大开源VLA模型。