




- @u010003835
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近博主在进行Hive测试 压缩解压缩的时候 遇到了这个问题,该问题也常出现在日常 hdfs 指令中, 在启动服务 与 hdfs dfs 执行指令的时候 :都会显示该提示,下面描述下该问题应该如何解决: 参考文章:Hadoop之—— WARN util.NativeCodeLoader: Unable to load native-hadoop library...
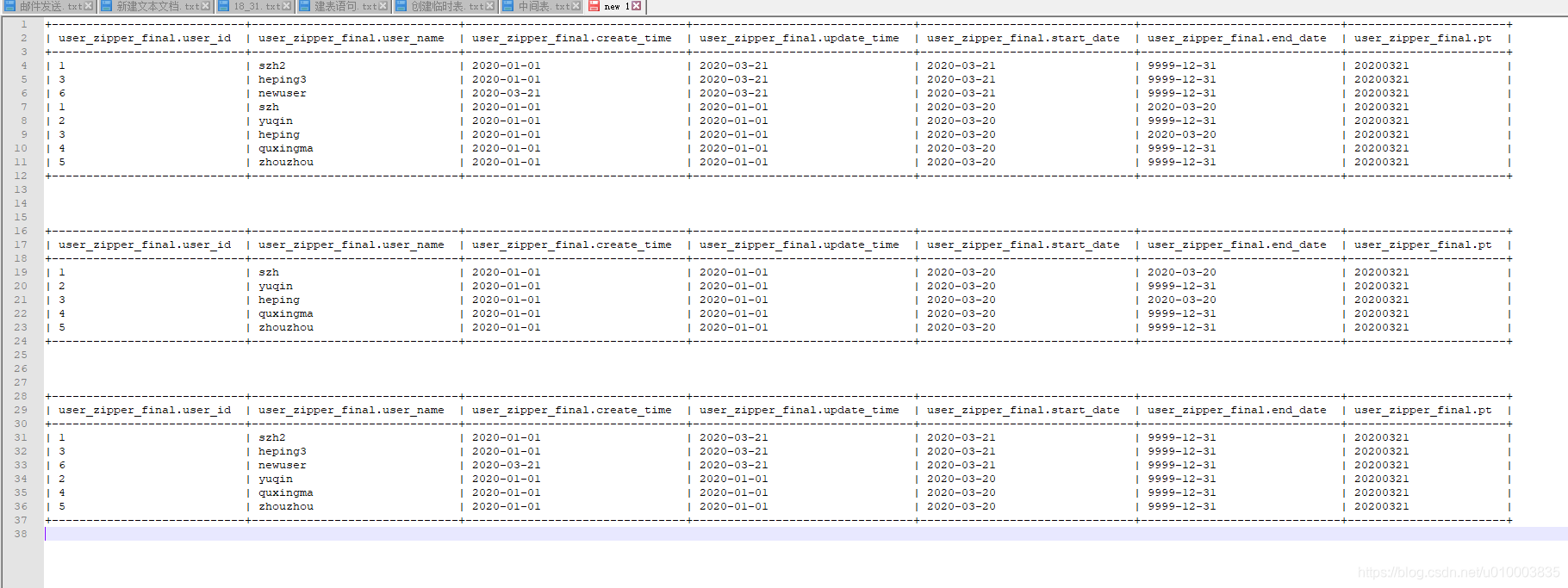
本篇文章,主要讲解1.什么是拉链表 以及 拉链表示例2.不同原始表情况下,拉链表如何构建。。。。。。
一 .KVM 简介KVM (名称来自英语: Kernel-basedVirtual Machine 的缩写,即基于内核的虚拟机) , 是一种用于Linux内核中的虚拟化基础设施,可以将Linux内核转化为一个hypervisor。KVM在2007年2月被导入Linux 2.6.20核心中,以可加载核心模块的方式被移植到FreeBSD及illumos上。KVM在具备Intel VT或
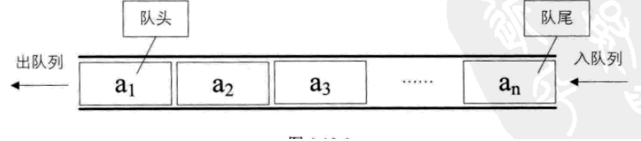
我们对基础的数据结构队列都非常的熟悉,这里回顾下队列是一种先进先出(First in First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头它有两个基本操作:offer在队列尾部加人一个元素poll从队列头部移除一个元素Java 中的队列可以利用实现 Deque 接口的类作为实现类,Deque 的实现类主要分为两种场景:一般场景LinkedList 大小可变的链
之前有面试官问到了parquet的数据格式,下面对这种格式做一个详细的解读。

最近看一篇文章对维度表进行了分类,记录一下。维度表主要分为两类高基数维度表和低基数维度表。

本篇文章,主要讲解1.什么是拉链表 以及 拉链表示例2.不同原始表情况下,拉链表如何构建。。。。。。
好特征可以从几个角度衡量:覆盖度,区分度,相关性,稳定性主要通过计算不同时间段内同一类用户特征的分布的差异来评估方差膨胀系数 Variance inflation factor (VIF)如果一个特征是其他一组特征的线性组合,则不会在模型中提供额外的信息,可以去掉评估共线性程度:2. 计算VF计算:VIF越大说明拟合越好,该特征和其他特征组合共线性越强,就越没有信息量,可以剔除使用排除法的方式训练

第一种 设置basePath的方法要求每个页面中都设置String path = request.getContextPath();String basePath =request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";%>
最近在做 React Native 开发, 遇到了一个问题,React Native 需要运行在 8081 端口,但是8081 端口被占用了。 可以通过以下方式 杀死 指定进程: 先通过 netstat -nao 查看所有的网络进程占用的端口 与 PID 如下:netstat -naoC:\Users\szh>netstat -ano活动连接...