




- @taichiXD
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今天在微调Llama-3.1-8B-Instruct模型时遇到了一个奇怪的错误。当我尝试使用QLoRA和PEFT进行微调时,程序报错提示。
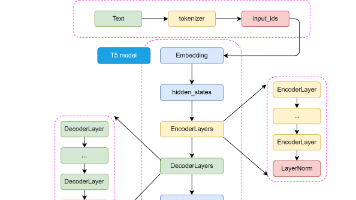
T5 模型最核心、最具影响力的理念是 “万物皆可文本生成”(Text-to-Text)。这个思想非常简洁而强大:无论是什么 NLP 任务,都将其统一转换为“输入一段文本,输出一段文本”的格式。这种方法极大地简化了模型设计和应用流程,我们不再需要为不同任务(如分类、问答、翻译)设计不同的模型输出层。翻译 (Translation):文本分类 (Text Classification):Positiv
对抗样本是对输入样本添加人眼无法察觉的细微干扰,导致模型以高置信度输出错误结果。对抗样本的分布通常偏离自然数据分布,与正常样本在模型中间层/输出层的分布存在差异。本文介绍了多种对抗样本的攻击以及防御的方法

T5 模型最核心、最具影响力的理念是 “万物皆可文本生成”(Text-to-Text)。这个思想非常简洁而强大:无论是什么 NLP 任务,都将其统一转换为“输入一段文本,输出一段文本”的格式。这种方法极大地简化了模型设计和应用流程,我们不再需要为不同任务(如分类、问答、翻译)设计不同的模型输出层。翻译 (Translation):文本分类 (Text Classification):Positiv
对抗样本是对输入样本添加人眼无法察觉的细微干扰,导致模型以高置信度输出错误结果。对抗样本的分布通常偏离自然数据分布,与正常样本在模型中间层/输出层的分布存在差异。本文介绍了多种对抗样本的攻击以及防御的方法
对抗样本是对输入样本添加人眼无法察觉的细微干扰,导致模型以高置信度输出错误结果。对抗样本的分布通常偏离自然数据分布,与正常样本在模型中间层/输出层的分布存在差异。本文介绍了多种对抗样本的攻击以及防御的方法
对抗样本是对输入样本添加人眼无法察觉的细微干扰,导致模型以高置信度输出错误结果。对抗样本的分布通常偏离自然数据分布,与正常样本在模型中间层/输出层的分布存在差异。本文介绍了多种对抗样本的攻击以及防御的方法
T5 模型最核心、最具影响力的理念是 “万物皆可文本生成”(Text-to-Text)。这个思想非常简洁而强大:无论是什么 NLP 任务,都将其统一转换为“输入一段文本,输出一段文本”的格式。这种方法极大地简化了模型设计和应用流程,我们不再需要为不同任务(如分类、问答、翻译)设计不同的模型输出层。翻译 (Translation):文本分类 (Text Classification):Positiv
T5 模型最核心、最具影响力的理念是 “万物皆可文本生成”(Text-to-Text)。这个思想非常简洁而强大:无论是什么 NLP 任务,都将其统一转换为“输入一段文本,输出一段文本”的格式。这种方法极大地简化了模型设计和应用流程,我们不再需要为不同任务(如分类、问答、翻译)设计不同的模型输出层。翻译 (Translation):文本分类 (Text Classification):Positiv
在Python开发中,配置一个独立的虚拟环境是非常重要的。它可以帮助我们隔离依赖,避免版本冲突,并确保项目在不同机器上的一致性。和 python -m venv,并教你如何将Conda环境打包为Docker镜像。
