




- @stephen147
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
现代大型语言模型(LLMs)基于Transformer架构,该架构利用注意力机制和多层感知器(MLP)来处理输入。基于流行的Transformer模型,例如GPT [10] 和 LLaMA [11],采用的是仅解码器结构。每个推理请求在逻辑上被划分为两个阶段:预填充阶段和解码阶段。在预填充阶段,所有输入token并行处理。此阶段生成第一个输出token,同时存储计算出的中间结果,这些中间结果被称为
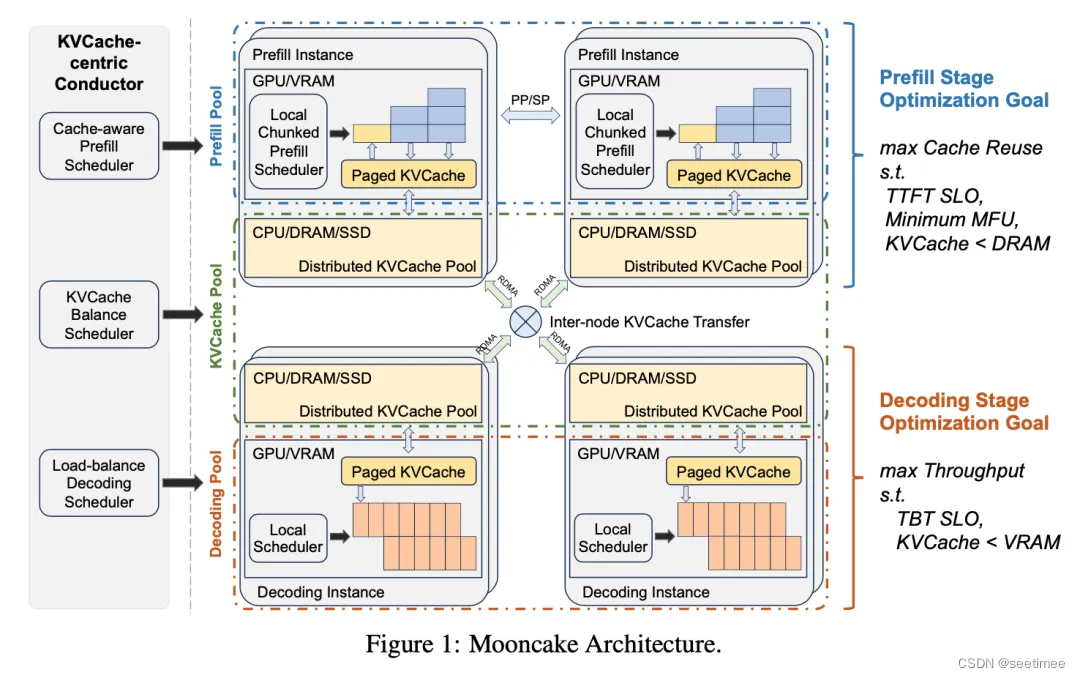
除英语和中文外,还接受过 27 种语言的数据培训显着提高编码和数学表现;Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 的扩展上下文长度支持高达 128K 令牌更详细的benchmark建议去看官网blog。
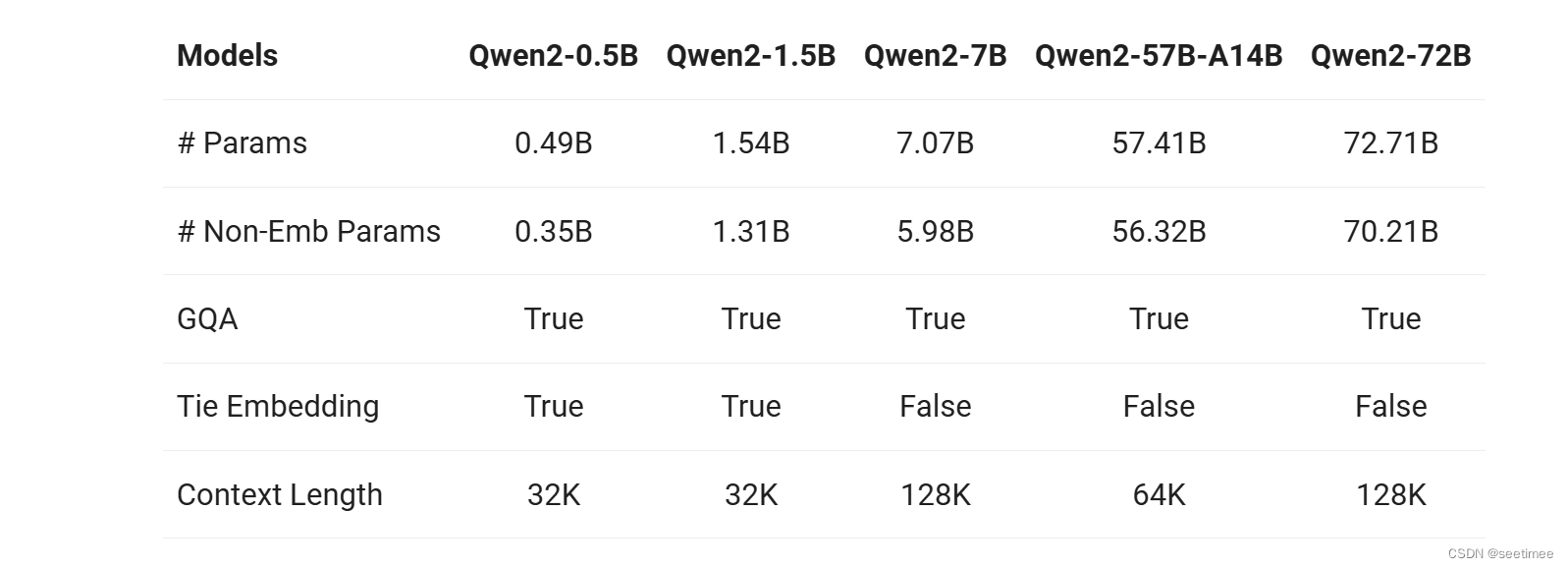
由于量化前的激活值变化范围较大,即使对于同一 token,不同channel数值差异较大,对每个 token 的量化也会造成精度损失,但是不难看出较大值一般出现在同一 channel,因此作者也分析了采用 per-channel 的量化方式,这种量化方式能很好的避免精度损失,但是硬件不能高效执行,增加了计算时间,因此大多数量化仍采用 per-token 及 per-tensor 的量化方式。最后,
7 月 2 日,微软开源了 GraphRAG,一种基于图的检索增强生成 (RAG) 方法,可以对私有或以前未见过的数据集进行问答。在 GitHub 上推出后,该项目快速获得了 2700 颗 star!开源地址:https://github.com/microsoft/graphrag通过 LLM 构建知识图谱结合图机器学习,GraphRAG 极大增强 LLM 在处理私有数据时的性能,同时具备连点成
这表示流式过程中的下一个块没有在规定时间内read出来,可能由于奇奇怪怪的原因总有个别请求中途出错,如果不设置read的超时时间在openai库中会设置成和timeout一样的时长,进而阻塞我们整体的响应时长,极大的音效体验。这里没有设置read参数,所以httpx库会设成和timeout一样的数值,你可以在创建openai类的时候手动设置timeout数值,比如。这里我read设的20s,大家可

原因:高版本的docker-compose好像已经不再支持 version这个标签,将version这一行注释即可正常运行这个是之前同事升级docker的时候没通知别人,然后之前的服务占用的网络标签依然还在docker网络中,使用命令查看特定网络的详细信息移除同名网络然后重启docker compose服务即可

原因:高版本的docker-compose好像已经不再支持 version这个标签,将version这一行注释即可正常运行这个是之前同事升级docker的时候没通知别人,然后之前的服务占用的网络标签依然还在docker网络中,使用命令查看特定网络的详细信息移除同名网络然后重启docker compose服务即可
随着大模型技术的不断发展,内容解析的方式正在发生深刻变革。大模型加持下的提示工程方法为爬虫技术带来了前所未有的便利和效率提升。然而,我们也应该意识到,这种方法并非万能之药,它仍然需要结合具体任务进行定制化的优化和调整。未来,我们期待看到更多关于大模型在爬虫领域的应用和研究,以推动这一技术的进一步发展和完善。

提示词总结的核心思想是在保持相似的语义信息的前提下,将原有提示词浓缩为更短的总结。这些技术还可以作为提示词的在线压缩方法。与前面提到的保留未裁剪标记的提示词裁剪技术不同,这一行方法将整个提示符转换为总结。RECOMP[34]引入了一个抽象压缩器(AbstractiveCompressor),其将输入问题和检索到的文档作为输入,生成一个简洁的摘要。具体来说,它从大规模的大模型中提取轻量级压缩器来进行

Milvus WeightedRanker 对比 RRF 重排机制下图说明了Milvus中混合搜索的执行过程,并强调了重排在这一过程中的作用。混合搜索中的重排是一个关键步骤,它整合了来自多个向量字段的结果,确保最终输出具有相关性并准确排序。:这种方法通过计算不同向量搜索得分(或向量距离)的加权平均值来合并结果。它根据每个向量字段的重要性分配权重。RRFRanker:这种策略基于不同向量列中的排名来
