




- @shuz0612
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
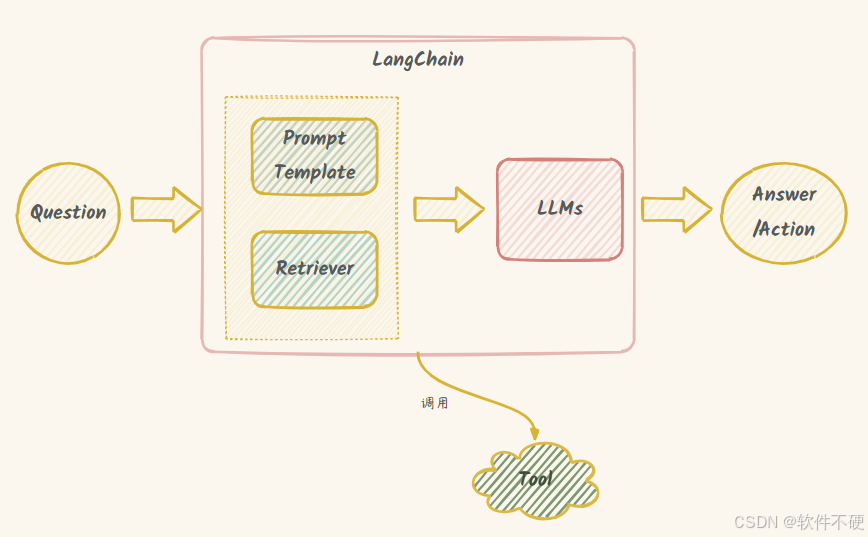
LangChain是一个开源框架,用于快速开发部署由LLM驱动的应用。LangChain使LLM不仅可以处理文本,还能够在更广泛的环境中进行操作和响应,从而扩展LLM的应用范围。如果把LLM比作CPU,那么LangChain类似于传感器。
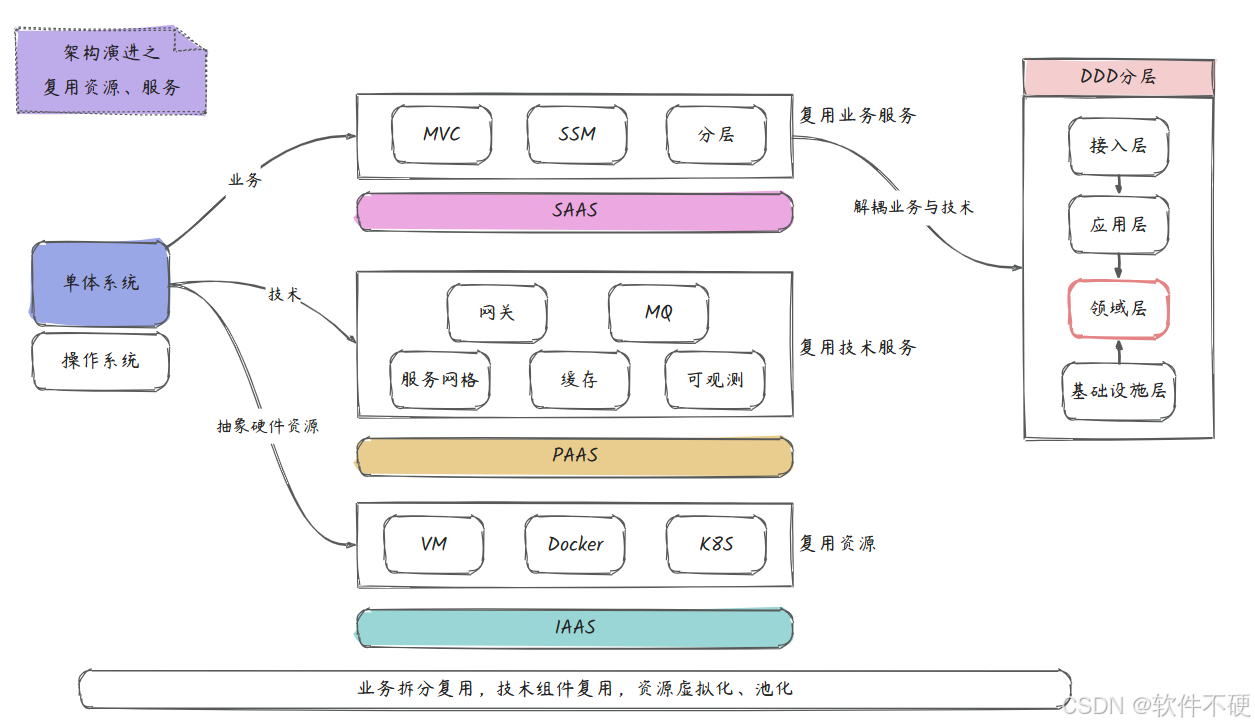
在软件系统的发展历程中,架构的演进始终围绕着如何更高效地复用资源与服务这一核心主题展开。从最初的单体架构开始,到今天已形成了多种成熟的架构模式和服务模型,每一步都体现了对可扩展、可复用和可维护性的不懈追求。

本文介绍了构建类GPT大语言模型的关键组件及其实现方法。首先阐述了层归一化技术如何通过调整激活值分布来提升训练稳定性,随后对比了ReLU、GELU等激活函数的特性,并实现了包含GELU的前馈神经网络模块。文章详细讲解了快捷连接在缓解梯度消失问题中的作用,以及如何将多头注意力机制与前馈网络结合形成Transformer块。最后展示了GPT模型的整体架构,包括文本生成机制从词元编码到解码的全过程,并指

LoRA(低秩自适应)是一种高效的参数微调技术,通过仅调整预训练模型权重的一小部分来适应特定任务。其核心思想是将权重更新矩阵ΔW分解为两个低秩矩阵A和B的乘积,显著减少训练参数。


PromptTemplate是里一个关键组件,其主要用途是构建和管理提示模板。借助,开发者能够把动态参数融入到提示文本里,进而生成个性化的提示信息,以此来和大语言模型进行交互最终获得更准确的回复。下面详细介绍。

本文介绍了大语言模型在文本分类任务上的微调方法,以垃圾短信分类为例。首先通过平衡数据集解决类别不平衡问题,并使用填充技术处理不同长度文本。然后修改预训练模型架构,替换输出层为二分类结构,并冻结大部分参数仅训练输出层。


注意力机制可以将输入元素转换为增强的上下文向量表示。自注意力机制通过对输入进行加权求和来计算上下文向量表示。使用矩阵乘法替代for循环,可以提高计算效率。引入了可训练的权重矩阵来计算输入的中间变换:查询矩阵、值矩阵和键矩阵。我们从一个基础版本的自注意力机制开始,然后逐步加入可训练的权重。因果注意力机制在自注意力的基础上增加了额外掩码,使得大语言模型可以一次生成一个单词。最后,多头注意力将注意力机制
