




- @shanglianlm
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Windows系统编译支持GPU的llama.cpp。
本文探讨目标检测模型评估指标mAP与生产环境关键指标(精确率、漏检率、误检率)的脱节问题。mAP作为综合指标无法直接反映生产场景的实际表现,常导致"实验室高分、现场效果差"的困境。文章提出5个改造方案:1)限定置信度区间的受限mAP;2)引入业务加权的加权mAP;3)按场景拆分的场景mAP;4)重构指标逻辑的业务等价mAP;5)统一评估规则。通过定制化改造,使mAP能准确反映生
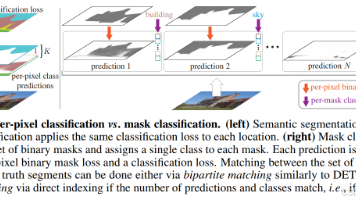
本文提出MaskFormer模型,将语义分割任务转化为预测一系列掩码及其全局类别,统一了语义分割、实例分割和全景分割任务。模型包含像素级模块、Transformer模块和分割模块三部分,通过并行预测N个概率-掩码对实现分割。实验表明,MaskFormer在ADE20K、Cityscapes等数据集上达到SOTA性能,尤其在全景分割任务中表现优异。该方法突破了传统逐像素分类的局限,为分割任务提供了新
1 break跳出for循环for(int i=0;i<100;i++){if(i==3)break;//break表示跳出整个for循环,也就是说,当i=10的时候,这个循环就结束了,之后执行for循环下面的代码。if(i==4)continue;// 跳出当前循环,执行下面的循环,就是说,当i=5的时候,跳出循环,从i=6开始继续循环}...
Rectangular trainingRectangular inferenceSquare InferenceRectangular Inference参考:https://github.com/ultralytics/yolov3/issues/232
1 安装yum -y install screen2 使用指定screen窗口的名称screen -S窗口名称 查看在后台的窗口screen -ls恢复离线的screen窗口screen -r窗口名称 暂时离开当前session, 丢到后台执行Ctrl+a+d-> detach关闭窗口exit...
本文地址:http://blog.csdn.net/shanglianlm/article/details/56012849数据库导出:使用sysdba 用户执行create or replace directory expdir as 'E:\bak';grant read,write on directory expdir to rm;使用cmd命令行执行
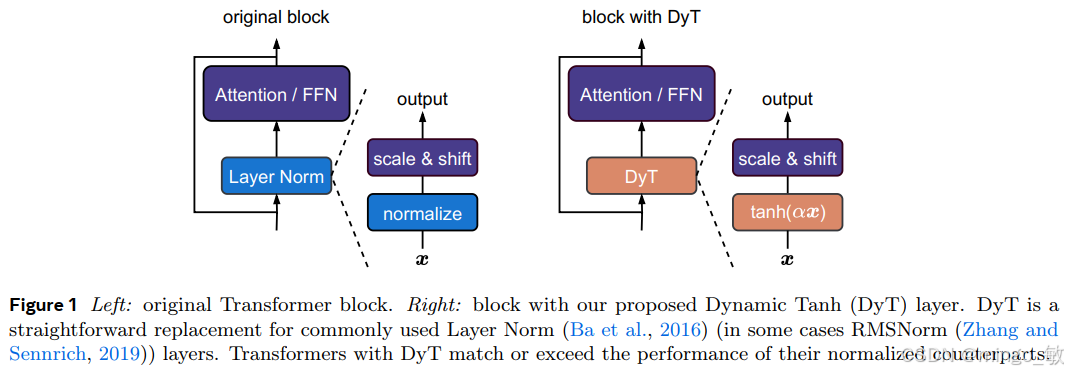
归一化层在现代神经网络中广泛应用且长期被视为不可或缺的组件。本研究突破性地证明,通过一种极为简洁的技术,无需归一化层的 Transformer 模型即可达到甚至超越传统架构的性能。本文提出动态双曲正切模块 DyT(Dynamic Tanh),其逐元素操作定义为 DyT (x) = tanh (αx),可直接替代 Transformer 中的归一化层。这一设计源于对 Transformer 中 La
deeplearning-default-valueFunctionsObject names in ChainerParameter names in ChainerChainerPyTorchTensorFlowdropoutratio0.5 (drop ratio)0.5 (drop ratio)Required (keep ratio)Links...
深度学习论文: Fast-SCNN: Fast Semantic Segmentation Network及其PyTorch实现Fast-SCNN: Fast Semantic Segmentation NetworkPDF:https://arxiv.org/pdf/1902.04502.pdfPyTorch: https://github.com/shanglianlm0525/PyTorch