




- @raw_inputhello
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
所以引入了“随即优先级采样”和“重要性采样”(重要性采样是以后总用于估计某一分布性质的方法,它的基本思想是,我们可以通过与带古迹分布不同的另一个分布中采样,然后通过采样样本的权重来估计待估计分布的性质)的技巧。状态或者说环境会发生变换,并且这些变化不是由于智能体的行为导致的,描述这个的特点的矩阵就是状态转移矩阵,状态转移矩阵是环境的一部分。不过经验回放的容量应当是有限的,不是由于成本导致的,而是因

所以引入了“随即优先级采样”和“重要性采样”(重要性采样是以后总用于估计某一分布性质的方法,它的基本思想是,我们可以通过与带古迹分布不同的另一个分布中采样,然后通过采样样本的权重来估计待估计分布的性质)的技巧。状态或者说环境会发生变换,并且这些变化不是由于智能体的行为导致的,描述这个的特点的矩阵就是状态转移矩阵,状态转移矩阵是环境的一部分。不过经验回放的容量应当是有限的,不是由于成本导致的,而是因
swap分区用于存储未使用的内存数据,可以帮助提高系统的性能和稳定性。建议将swap分区的大小设置为内存容量的1.5倍,比如计算机有8GB内存的话,可以将swap分区的大小设置为12GB。3. /home分区用于存储用户文件和设置信息,因此如果Ubuntu系统中有多个用户,或者需要在Ubuntu系统中存储大量的文件和数据,建议单独划分/home分区。建议将/home分区的大小设置为要存储的文件和数

深度学习是机器学习的一个子领域,它试图模拟人脑的工作原理,通过训练大量数据来自动学习数据的内在规律和表示层次。深度学习的核心是神经网络,特别是深度神经网络,即包含多个隐藏层的神经网络。这些隐藏层可以自动学习数据的多层次表示,从而实现对复杂数据的高效处理。深度学习是机器学习的一个子领域,它试图模拟人脑的工作原理,通过训练大量数据来自动学习数据的内在规律和表示层次。深度学习的核心是神经网络,特别是深度

对的系列的学习(大佬的完整代码在2022年人工智能依旧飞速发展,从传统机器学习模型到如今以“炼丹”为主的深度神经网络,代表着模型拟合度与模型各自的发展趋势。至此,深刻体会并成功解释NN为何能取得更优的效果成为各行各业的新目标,而可解释性机器学习便应运而生。
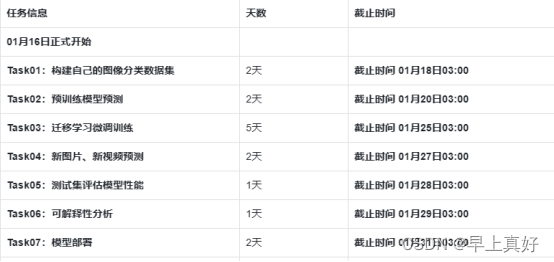
众所周知,国产大模型如千问、书生、易等等都有开源大模型,但是出场时效果就很不错的讯飞星火大模型却迟迟没有见到开源的消息,原来是憋了发大的啊!今天下午收到了讯飞星火发布会的微信推送属实是挺期待的。讯飞大模型定制训练平台。
深度学习是机器学习的一个子领域,它试图模拟人脑的工作原理,通过训练大量数据来自动学习数据的内在规律和表示层次。深度学习的核心是神经网络,特别是深度神经网络,即包含多个隐藏层的神经网络。这些隐藏层可以自动学习数据的多层次表示,从而实现对复杂数据的高效处理。深度学习是机器学习的一个子领域,它试图模拟人脑的工作原理,通过训练大量数据来自动学习数据的内在规律和表示层次。深度学习的核心是神经网络,特别是深度
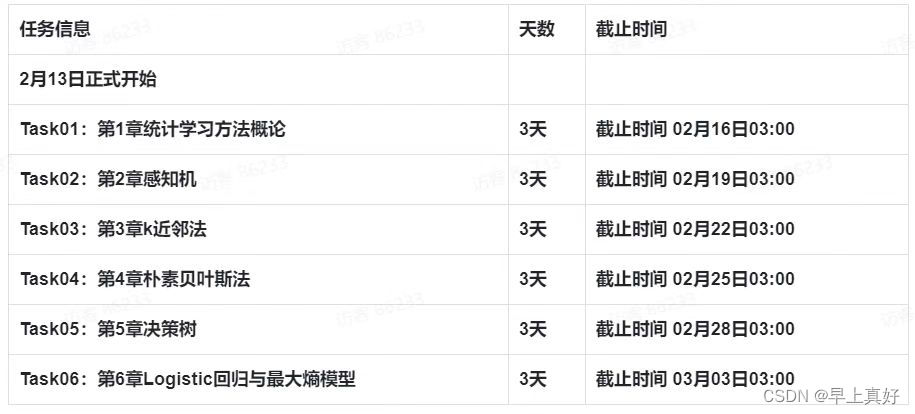
本次参加的是DataWhale组织的2023年2月份学习计划。学习内容为李航老师的《统计学习方法(第二版)》的第一到六章。习题的解答开源在datawhale的GitHub账号。
众所周知,国产大模型如千问、书生、易等等都有开源大模型,但是出场时效果就很不错的讯飞星火大模型却迟迟没有见到开源的消息,原来是憋了发大的啊!今天下午收到了讯飞星火发布会的微信推送属实是挺期待的。讯飞大模型定制训练平台。
对的系列的学习(大佬的完整代码在2022年人工智能依旧飞速发展,从传统机器学习模型到如今以“炼丹”为主的深度神经网络,代表着模型拟合度与模型各自的发展趋势。至此,深刻体会并成功解释NN为何能取得更优的效果成为各行各业的新目标,而可解释性机器学习便应运而生。