




- @qq_63075864
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
modelexplain:可以指定训练用的模型,参数内容是可以是pt、yaml文件路径,也可以不指定,好像会默认加载最新的YOLO模型,比如现在是YOLOv11dataexplain:指定数据配置文件,配置文件应该包括训练样本与测试样本的数据路径、每个类的名字以及标号arg:epochstype:int很明显,不介绍了arg:timetype:float。
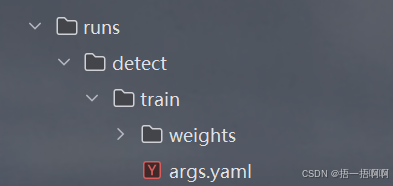
去往cos控制台,找到跨域访问cors设置,把自己的vue所在地址配置上去即可。解决办法:去腾讯云对象存储界面配置跨域规则。
在终端或命令行安装jupyter和notebook。
均方误差(MSE):是预测值与真实值之差的平方和的平均值,其数学表达式为,其中为样本数量,为第个样本的真实值,为第个样本的预测值。平均绝对误差(MAE):是预测值与真实值之差的绝对值的平均值,其数学表达式为。

fo = open("C:\\Users\\ASUS\\Desktop\\python有关文件\\教你如何爬取网页.txt",'w',encoding="utf-8")然后打开网页Convert curl commands to code,将刚刚复制的内容输入,得到代码。复制进vscode(注意response的网址不要按他给的,自己复制网址放上去)这里获取的网页没有cookie,有些是有的,如下

你是否和我一样,不想每次启动mongodb服务都要从命令行运行mongod命令,又或者不想下载MongoDB Compass等软件完成自动启动(因为我之前下过这个软件,记忆中它好像能实现开机自启动mongodb),那么,设置自启动的教程来啦!2.在D:\Program Files\MongoDB\data(每个人的不同,替换成MongoDB的安装目录就可以了)下新建文件夹log(存放日志文件)并且

语法中,变量的作用域由自动注入的上下文管理,因此在函数外部定义的变量会在整个组件中共享。然而,Vue Router的。中出现问题,因为Vue组件的生命周期外部,Vue Router可能无法正确注入。是一个依赖于组件实例的函数,因此在组件外部使用它可能会导致一些问题。函数内部创建的,而不是在组件的生命周期外创建。解决办法,把$router的定义挪到login函数外部即可。

那如果是加上不同的数呢,比如说往区间[l,r]的l点加上数a,往l+1点加上数a+d,……这时可以用二阶差分。因为你想,对加上对应等差数列的不同的数进行一阶差分,是不是点的值都变成公差了,公差是不是都是一样的,那这时候再进行一次差分,就可以做到只改变区间某点的数据,实现区间的加减值。众所周知,在往区间的每一个数都加上一个相同的数k,进行n次后会得到一个新的数列,如果每次加都循环区间挨个数加上k,这

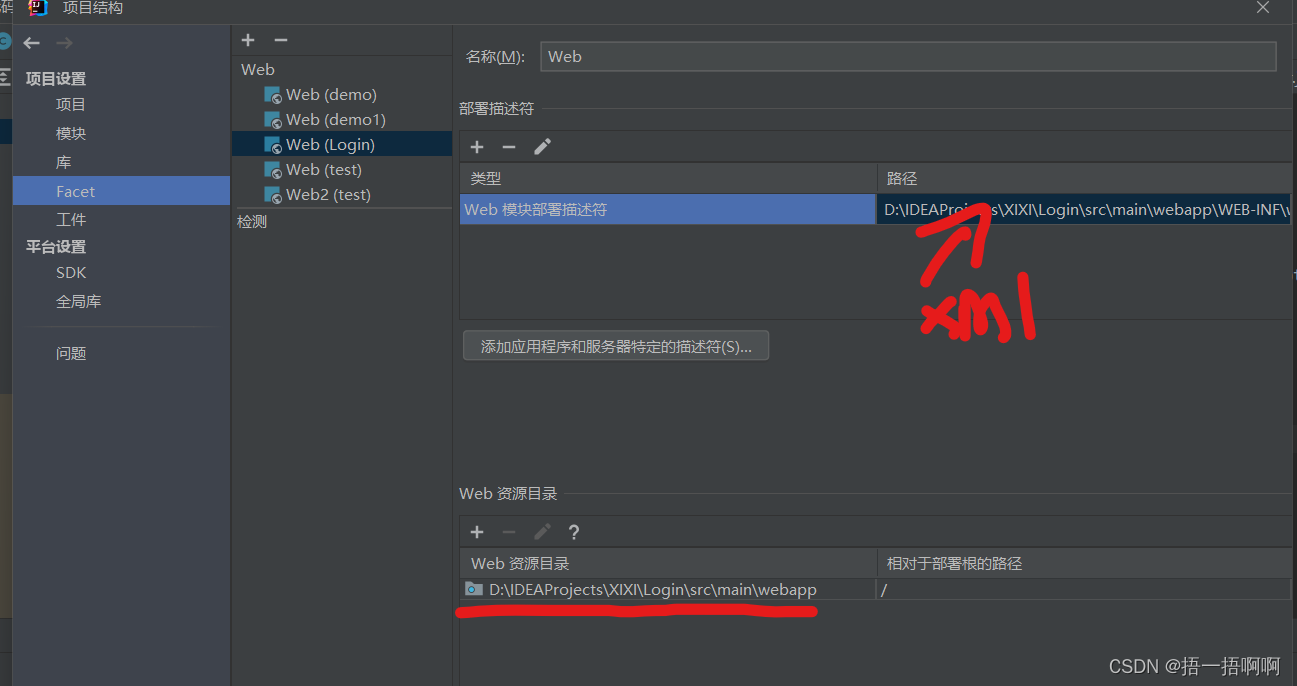
但是我碰到了种问题,用工件构建的输出目录,里边没有web.xml和jsp文件等,但我放置web部署文件的位置等也都找对了,这个也会导致访问404,不知道为什么工件没有将web.xml文件导出。原因:可能是放置web部署文件的位置没有找对,如下图,上边是放置部署文件web.xml的位置,下边是自己放web资源的位置。
在终端或命令行安装jupyter和notebook。