- @qq_60090693
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
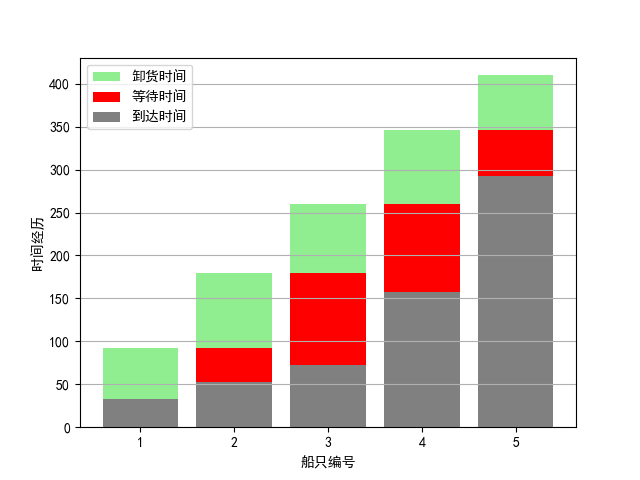
零、前言引例:投针实验蒙特卡洛模拟&仿真的基本介绍实例一、三门问题实例二、排队问题1-港口卸货实例三、排队问题2-银行排队实例四、有约束的非线性规划实例五、书店选择(0-1规划)实例六、导弹追踪实例七、旅行商问题实例八、加油站存储策略实例九、决策问题实例十、双旅行商问题
本文 “Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer” 提出了一种基于任意风格迁移的对抗攻击方法(STM),旨在提升对抗样本的可迁移性,应对深度神经网络在对抗攻击下的安全问题。

本文 “Towards Transferable Targeted 3D Adversarial Attack in the Physical World” 提出了一种全新的 3D 攻击框架 TT3D,可将多视图图像快速重建为可迁移目标性的 3D 对抗样本,有效填补了 3D 可迁移目标性攻击领域的空白,为研究深度学习系统的安全性提供了新的视角和方法。

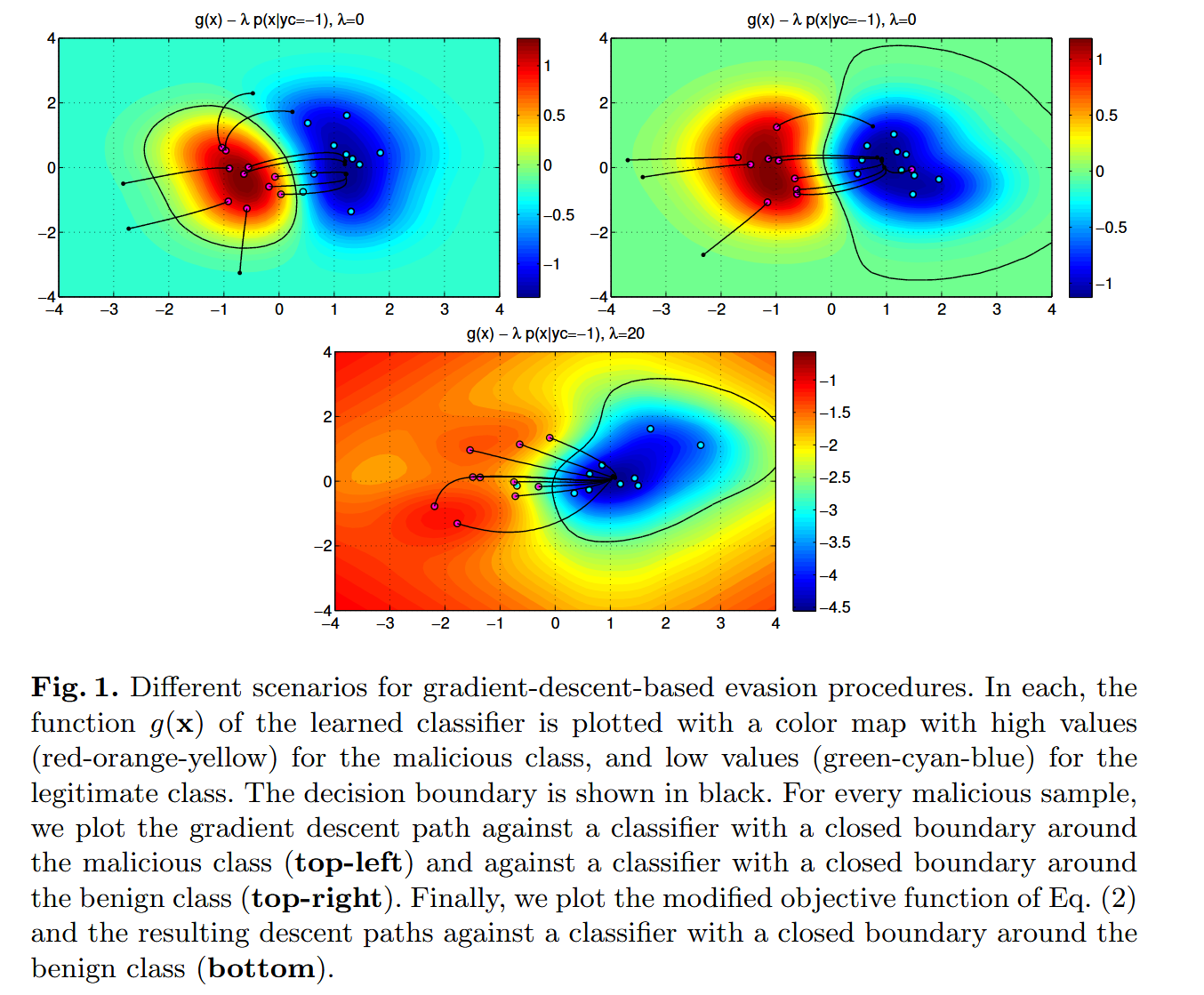
本文 “Evasion attacks against machine learning at test time” 提出一种基于梯度的方法评估分类算法在规避攻击下的安全性,通过模拟不同风险级别的攻击场景,发现常用分类算法易受攻击,并给出了改进安全性的建议。
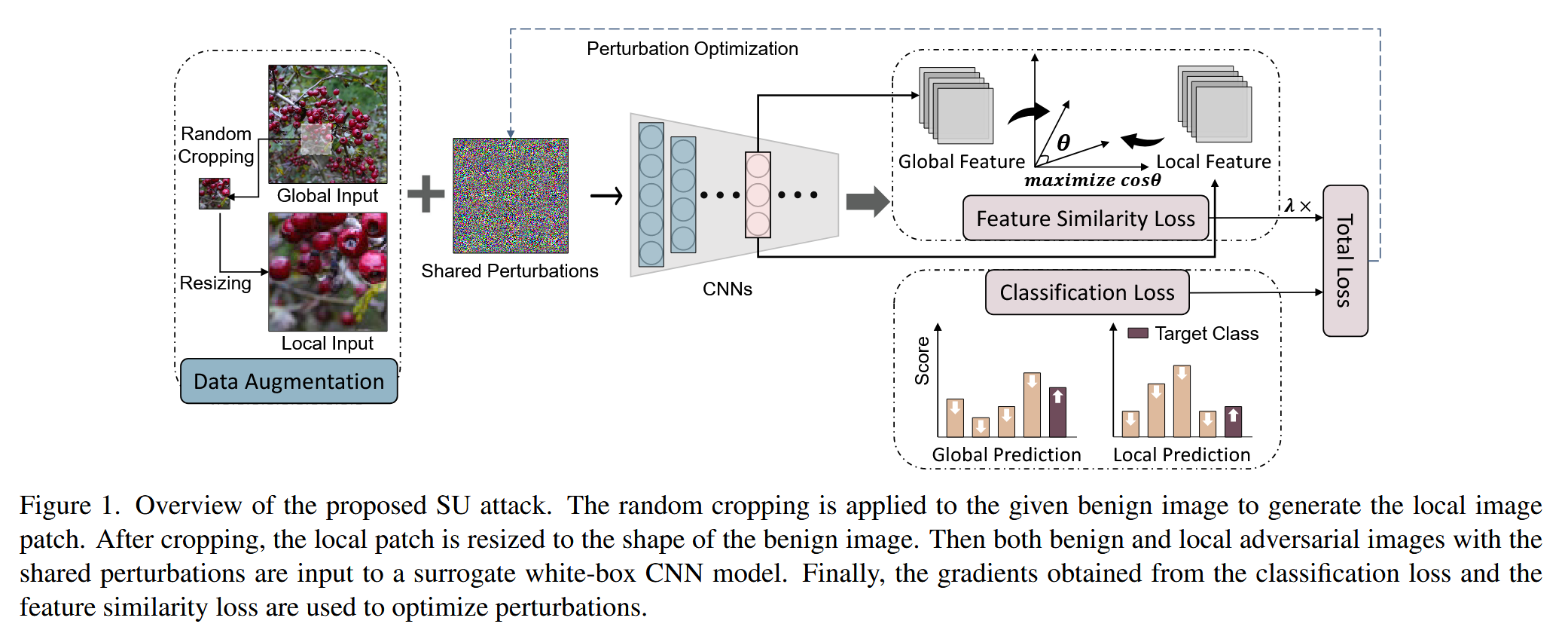
本文 “Enhancing the Self-Universality for Transferable Targeted Attacks” 提出了一种基于自通用性(Self-Universality,SU)的可迁移目标性攻击方法,旨在无需辅助网络额外训练的情况下提升对抗扰动的可迁移性,增强深度学习模型在现实应用中的安全性
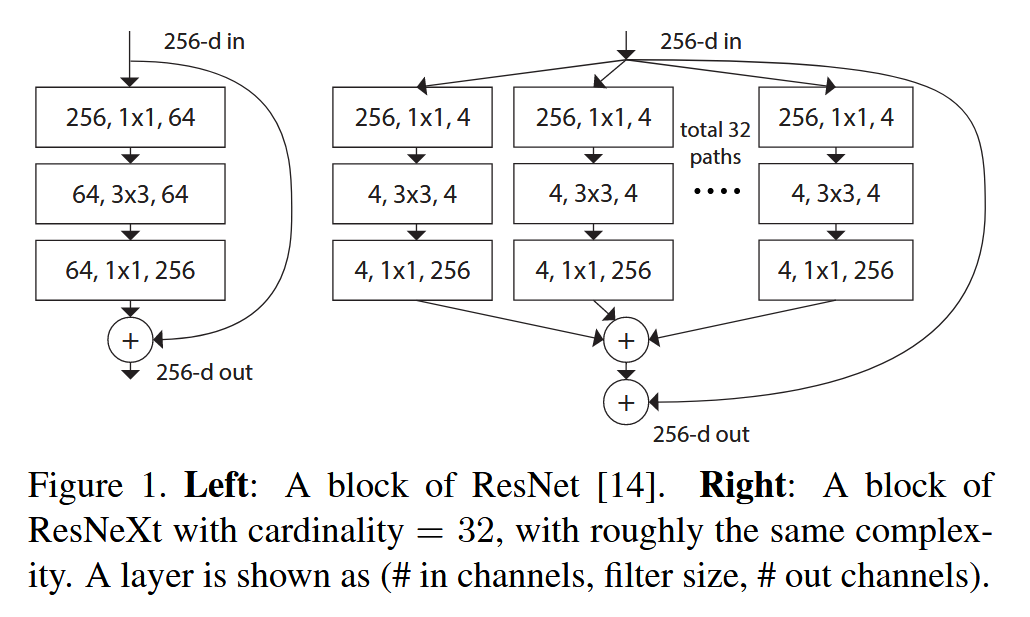
本文 “Aggregated Residual Transformations for Deep Neural Networks” 提出了一种简单且高度模块化的图像分类网络架构ResNeXt。它重复具有相同拓扑结构的构建块来聚合一组变换,引入 “基数” 概念,通过实验证明在保持计算复杂度和模型大小的情况下,增加基数能提高分类准确率,且比加深或加宽网络更有效
Vision Transformers(ViTs)在计算机视觉领域取得显著成果,但易受对抗攻击。本文深入剖析其表征漏洞,发现对抗扰动在早期层影响微弱,随后在网络中传播并放大。基于此,提出 NeuroShield-ViT 防御机制,通过选择性中和早期层脆弱神经元来抵御攻击。

本文提出数据高效的图像 Transformer(DeiT),仅在 Imagenet 上训练就能得到与卷积神经网络(convnets)性能相当的无卷积 Transformer。引入基于蒸馏 token 的师生策略,该策略能让学生模型通过注意力机制向教师模型学习,尤其是以 convnet 为教师时效果显著,使得 DeiT 在 Imagenet 上最高可达 85.2% 的准确率,且在迁移学习任务中表现出

本文 “Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning” 提出了一种名为 Multiple Asymptotically Normal Distribution Attacks(MultiANDA)的方法,旨在通过学习对抗扰动的分布来生成具有强转移性的

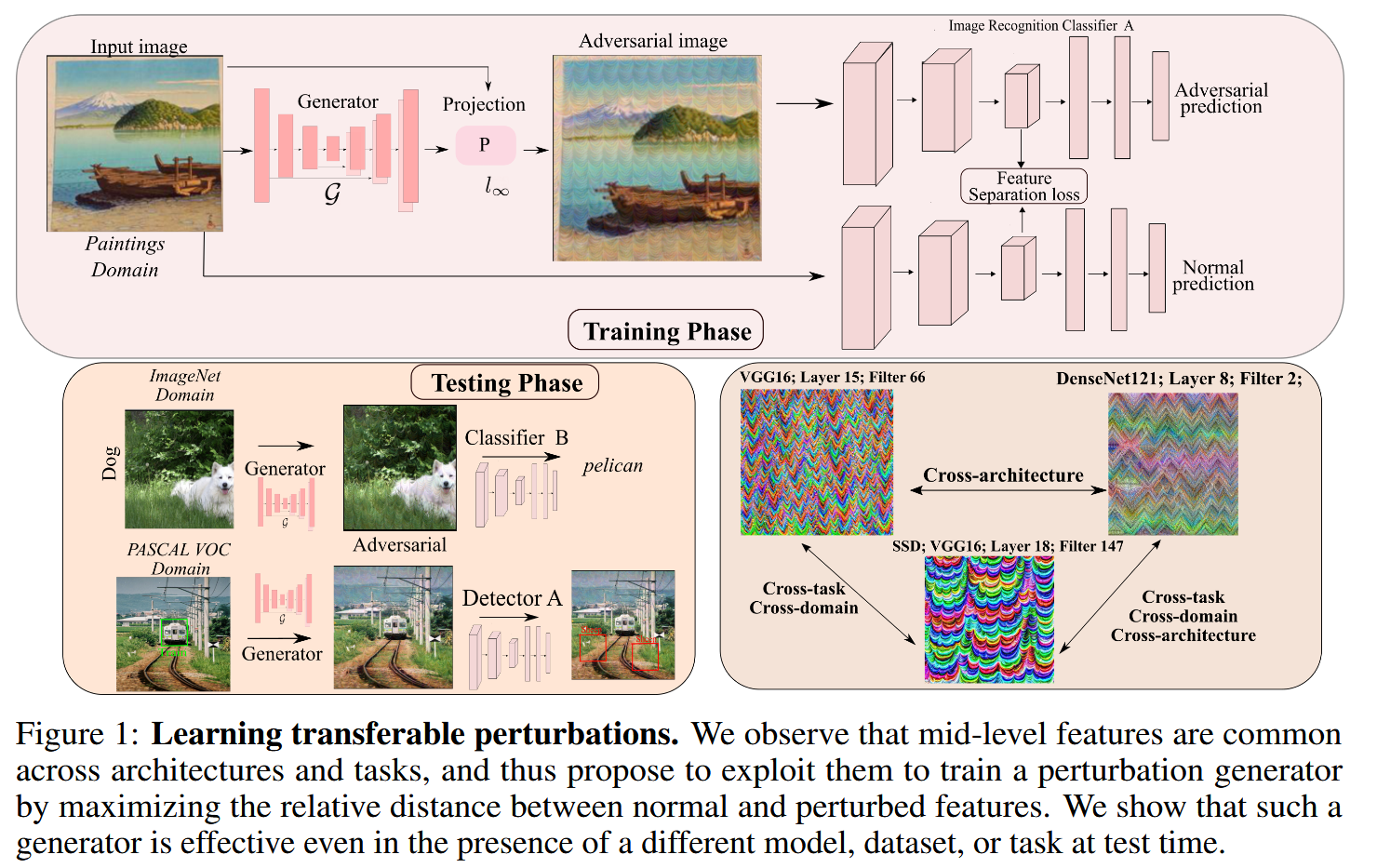
本文 “Learning Transferable Adversarial Perturbations” 主要研究生成对抗扰动的可转移性,提出利用深度神经网络(DNN)的中层特征训练扰动生成器,以提高对抗扰动在不同目标架构、数据和任务之间的可转移性,实验表明该方法优于现有攻击策略。