




- @qq_59444334
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
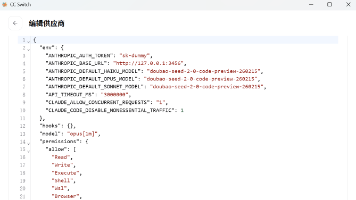
本文分享了使用火山引擎豆包2.0 Code模型接入Claude Code的实践过程。作者尝试了多种代理方案,最终发现Claude-Code-Router是接入最佳解决方案,能完美支持工具调用功能。文章详细介绍了安装配置步骤,包括创建配置文件、启动服务、设置Claude Code环境变量等关键操作,并提供了工具调用的测试用例。通过对比不同方案的优缺点,证实Claude-Code-Router具有配置
摘要:本文介绍了Clawdbot配置中常见问题的解决方案。核心配置包括models模块(需设置豆包1.8模型参数)和agents模块(关联智能体与模型),强调baseUrl、model.id等关键参数不可修改。配置生效需替换原有节点并重启网关,特别注意将"reasoning"设为false以避免无响应问题。配置文件路径可通过Cursor和Trae工具修改。配置完成后需检查日志确
本文分享了使用火山引擎豆包2.0 Code模型接入Claude Code的实践过程。作者尝试了多种代理方案,最终发现Claude-Code-Router是接入最佳解决方案,能完美支持工具调用功能。文章详细介绍了安装配置步骤,包括创建配置文件、启动服务、设置Claude Code环境变量等关键操作,并提供了工具调用的测试用例。通过对比不同方案的优缺点,证实Claude-Code-Router具有配置
本文通过实验验证了如何利用公开内容平台影响AI推荐结果。作者虚构"智引GEO"公司,分析豆包AI的推荐机制主要由实时RAG检索决定,其来源多为今日头条、搜狐号等平台。实验发现,要影响AI推荐,需要在多个平台发布符合规范的内容(避免直接广告,提供行业分析),并通过批量生成不同城市、行业的文章来建立内容矩阵。虽然初期发文被拒,但调整写作风格后通过率提升。实验证明,利用现有工具和内容
摘要:本文介绍了Clawdbot配置中常见问题的解决方案。核心配置包括models模块(需设置豆包1.8模型参数)和agents模块(关联智能体与模型),强调baseUrl、model.id等关键参数不可修改。配置生效需替换原有节点并重启网关,特别注意将"reasoning"设为false以避免无响应问题。配置文件路径可通过Cursor和Trae工具修改。配置完成后需检查日志确
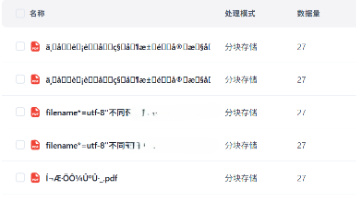
【摘要】本文针对FastGPT中文文件名上传乱码问题提出解决方案。关键发现服务端需URL编码(Percent-encoding)而非RFC2231或UTF-8原始字节。通过Python的quote_plus()模拟Java URLEncoder,结合requests自动处理文件句柄,完美匹配服务端预期。方案包含重试机制、完整响应日志及批量导入功能,经测试成功解决中文PDF上传乱码问题。技术亮点包括
摘要:本文总结了在Windows环境下部署OpenAgents框架时常见的编码兼容、环境变量配置及大模型适配问题。主要问题包括Windows终端GBK编码导致Emoji符号报错,可通过修改系统为UTF-8编码解决;环境变量命名规则混淆(DEFAULT_*与OPENAI_*前缀的区分)导致模型调用失败;阿里通义千问和火山引擎方舟等第三方模型的适配错误,涉及模型名、接口地址和变量名的精准匹配。文章提供

本文总结了利用大模型从科学文献PDF中提取关键词和对应值的实践经验。通过PDF转文本、关键词提取和提示词优化,正确率从初始较低水平提升至95%。关键改进包括:1)采用LaTeX标准格式处理化学符号;2)优化提示词策略,增加对比表、差异表和值范围表;3)建立三级提取验证流程(生成者-评审者-仲裁者);4)使用PaddleOCR将PDF转为结构化Markdown格式。研究发现模型选择(闭源优于开源)、
