




- @qq_52859223
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
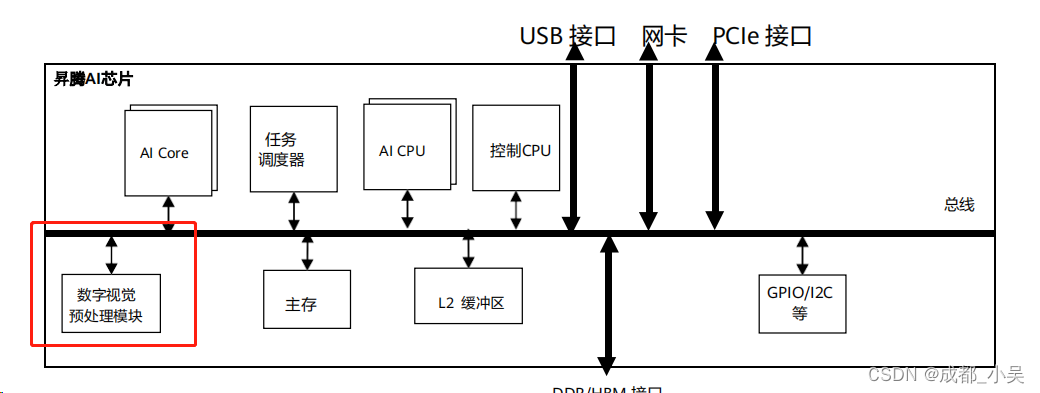
自从毕业后开始进入了华为曻腾生态圈,现在越来越多的公司开始走国产化路线了,现在国内做AI芯片的厂商比如:寒武纪、地平线等,虽然我了解的不多,但是相对于瑞芯微这样的AI开发板来说,华为曻腾的生态比瑞芯微好太多了,参考文档非常多,学习资料也有很多,也容易上手开发。现在应用较广泛的目标检测算法从最开始的yolov5一直到现在的yolov8,虽然只是简单的看了一下算法的原理,整体来说yolo的更新还是针对

本文主要讲解基于华为大模型推理服务框架以及langchain gradio搭建本地知识库系统。
对于大家没有足够的Ascend硬件资源,手里只有一块开发板,而且内存不足的时候,CANN-TOOLKIT也支持在非昇腾的设备上进行安装,就比如我们在windows上安装linux-ubuntu的虚拟机,虚拟机里面进行安装该软件,但是在安装的过程中大家会遇到一个问题,就是在非root用户下进行安装,在安装的时候没有加必要的参数,所以建议大家也可以所有操作都在root用户下操作,包括模型转换以及安装过

准备出山。
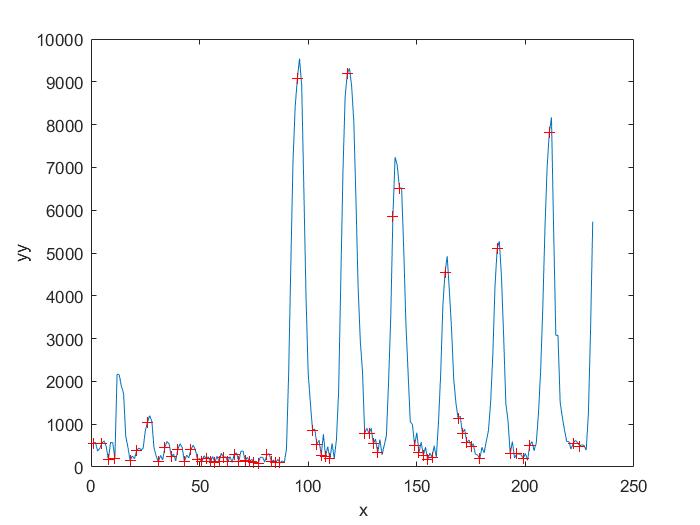
(3)使用opencv解码出来之后的图片是,bgr,uint8,NHWC格式的图片,对于不同的模型输入,需要进行转换为模型需要的输入,比如resize缩放图片指定大小,数据格式转换从uint8 到float32 16\以及通道的变换,这一步也是大家的预处理。(2)直接使用opencv的api进行读取,也就是解码,其实opencv读取视频还是蛮快的,读取rtsp确实有一些慢,而且还占用cpu的资源,
RK1808编译opencv
rk3588_yolov5
对于大家没有足够的Ascend硬件资源,手里只有一块开发板,而且内存不足的时候,CANN-TOOLKIT也支持在非昇腾的设备上进行安装,就比如我们在windows上安装linux-ubuntu的虚拟机,虚拟机里面进行安装该软件,但是在安装的过程中大家会遇到一个问题,就是在非root用户下进行安装,在安装的时候没有加必要的参数,所以建议大家也可以所有操作都在root用户下操作,包括模型转换以及安装过
自从毕业后开始进入了华为曻腾生态圈,现在越来越多的公司开始走国产化路线了,现在国内做AI芯片的厂商比如:寒武纪、地平线等,虽然我了解的不多,但是相对于瑞芯微这样的AI开发板来说,华为曻腾的生态比瑞芯微好太多了,参考文档非常多,学习资料也有很多,也容易上手开发。现在应用较广泛的目标检测算法从最开始的yolov5一直到现在的yolov8,虽然只是简单的看了一下算法的原理,整体来说yolo的更新还是针对
随着各大公司的国产化要求,慢慢的涌入华为的曻腾加速卡,相比英伟达来说,大家可能很难再去购买。如上所示:选择需要加入的磁盘,点击enter进行选择;更改之后选择 Apply changes ->选择Confirm->选择Yes;然后进如/etc/sysconfig/network-script/eop125s0f0文件进行编译;保存配置save configuration -> confirm->Y
