




- @qq_52302919
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
论文链接: https://arxiv.org/pdf/2207.03620.pdfcode: https://github.com/VITA-Group/SLaKlink自视觉Transformers(ViTs)出现以来,Transformers迅速在计算机视觉界大放异彩。卷积神经网络(CNN)的主导地位似乎受到越来越有效的基于Transformers的模型的挑战。最近,几个先进的卷积模型在局部

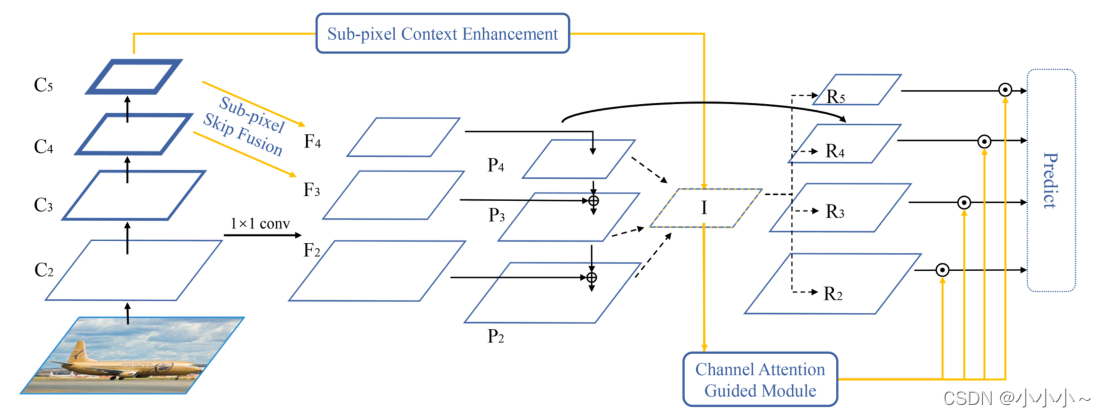
论文链接: https://arxiv.org/pdf/2103.10643v1.pdf本文提出了一种新的通道增强特征金字塔网络(CE-FPN),具体地说,受亚像素卷积的启发,提出了一种亚像素跳跃融合方法来执行通道增强和上采样。它代替了原来的1×1卷积和线性上采样,减轻了由于通道减少而造成的信息损失。然后,提出了一种亚像素上下文增强模块,用于提取更多的特征表示,由于通过亚像素卷积利用了丰富的通道信
一、BlurPool论文地址:https://arxiv.org/abs/1904.11486论文:BlurPool:Making Convolutional Networks Shift-Invariant Again论文中给出的原因,是因为stride=2的时候卷积和pool等下采样操作时,违反了采样定理,会导致信号走样,其实这个问题在很久之前就有所说明,就比如我们在构建高斯、拉布普斯金字塔的

在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立摄像机成像的几何模型,这些几何模型参数就是摄像机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数的过程就称之为相机标定。简单来说是从世界坐标系换到图像坐标系的过程,也就是求最终的投影矩阵P的过程。无论是在图像测量或者机器视觉应用中,摄像机参数的标定都是非常关键的环节,

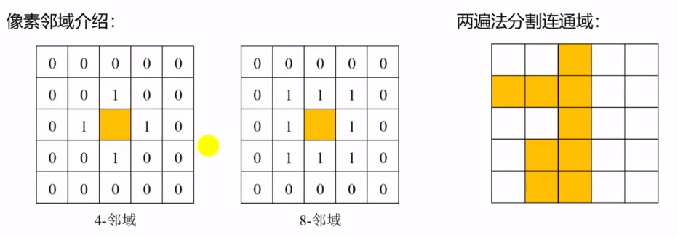
邻域分为4邻域和8邻域。ltype:输出图像的数据类型,目前只支持CV_32s和lCV_16U这两种数据类型,默认参数值为CV_328。stats:不同连通域的统计信息矩阵,矩阵的数据类型为Cv_32S。ltype:输出图像的数据类型,目前支持CV_32S和CV_16U两种数据类型,默认参数为CV_32S。connectivity:标记连通域时使用的邻域种类,4表示4-邻域,8表示8-邻域,默认参
一、卷积层、激活函数层、池化层、全连接层1、卷积层:一般的,标准数码相机的图像将有三个通道——红、绿、蓝——我们可以把它们想象成三个相互叠加的2d矩阵(每种颜色一个),每个像素值在0到255之间(颜色越亮数值越大)。卷积在卷积网络中的主要目的是从输入图像中提取特征。卷积通过使用输入数据的小方块学习图像特征来保持像素之间的空间关系。下面仅以0,1的二维矩阵进行举例(实际过程中为0-255)。三通道中
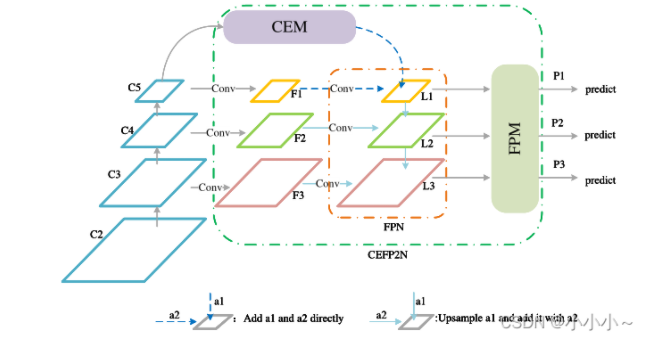
由于分辨率低、体积小,微小物体很难被探测到。微小目标检测性能差的主要原因是网络的局限性和训练数据集的不平衡性。本文提出了一种新的特征金字塔网络,将上下文增强和特征细化相结合。将多尺度扩展卷积得到的特征进行融合,并自上而下注入特征金字塔网络,以补充上下文信息。在多尺度特征融合中,引入通道和空间特征细化机制来抑制冲突形成,防止微小物体被淹没在冲突信息中。
使用体素化网格方法实现下采样,即减少点的数量减少点云数据,并同时保存点云的形状特征,在提高配准,曲面重建,形状识别等算法速度中非常实用,PCL是实现的VoxelGrid类通过输入的点云数据创建一个三维体素栅格,容纳后每个体素内用体素中所有点的重心来近似显示体素中其他点,这样该体素内所有点都用一个重心点最终表示,对于所有体素处理后得到的过滤后的点云,这种方法比用体素中心逼近的方法更慢,但是对于采样点

NMS即(non maximum suppression)即非极大抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值。在最近几年常见的物体检测算法(包括rcnn、sppnet、fast-rcnn、faster-rcnn等)中,最终都会从一张图片中找出很多个可能是物体的矩形框,然后为每个矩形框为做类别分类概率。......

最近的VisionTransformer(ViT)模型在各种计算机视觉任务中表现优异,这得益于它能够通过自注意对图像块或标记的长期依赖进行建模。然而,这些模型通常在每一层中每个token特征指定指定的感受野。这种约束不可避免地限制了每个自注意力层对多尺度特征的捕获能力,从而导致对不同尺度多目标图像的处理性能下降。为了解决这个问题,作者提出了一种新的通用策略,称为分流自我注意(SSA),它允许VIT
